Nota: El contenido de esta sección es una adaptación al formato Quarto del capítulo 2 sección 3 del libro Introducción a la Estadística Inferencial de Luis Rincón (2019).
Este importante método para estimar parámetros fue difundido ampliamente por Ronald A. Fisher a través de varios trabajos publicados durante la década de 1920. Sin embargo, la idea de máxima verosimilitud ya había sido propuesta con anterioridad por mátemáticos importantes como Pierre-Simon Laplace y por Carl Friedrich Gauss.
Para plantear este método, primero definiremos una función llamada de verosimilitud. Tomaremos como base una colección de variables aleatorias cuya distribución depende de un parámetro desconocido que se quiere estimar.
Definición 3.1 La función de verosimilitud de un vector de variables aleatorias \((X_1, X_2, \ldots, X_n)\) cuya distribución depende de un parámetro \(\theta\) se define como la función de densidad o de probabilidad conjunta
3.1 La letra \(L\) procede del término en inglés Likelihood, que tradicionalmente se ha traducido como verosimilitud.
Como la notación lo sugiere, nos interesa estudiar a \(L(\theta)\) como una función del parámetro \(\theta\), manteniendo fijos los valores observados \(x_1, x_2, \ldots, x_n\). Los valores de este parámetro se encuentran en cierto espacio parametral \(\Theta\), y ese es el dominio de definición de la función de verosimilitud.
Observemos que en la definción de \(L(\theta)\) no se está está suponiendo necesariamente que las variables aleatorias \(X_1, X_2, \ldots, X_n\) constituyen una muestra aleatoria. Si estas son independientes, entonces la función de verosimilitud puede expresarse como el producto de las funciones de densidad o de probabilidad marginales, es decir,
En la mayoría de los casos prácticos, se trabaja con muestras aleatorias, por lo que la última expresión es la más común.
TipMétodo de máxima verosimilitud
El método de máxima verosimilitud consiste en encontrar el valor del parámetro \(\theta\) que maximiza la función de verosimilitud \(L(\theta)\). Al valor de \(\theta\) que logra esta maximización se le llama estimación de máxima verosimilitud o estimación máxima verosímil y se denota por \(\hat{\theta}_{mv}\).
La idea intuitiva detrás de este método es que el valor del parámetro \(\theta\) es aquel que hace más probable la ocurrencia de los datos observados \(x_1, x_2, \ldots, x_n\). Veamos ahora algunos ejemplos.
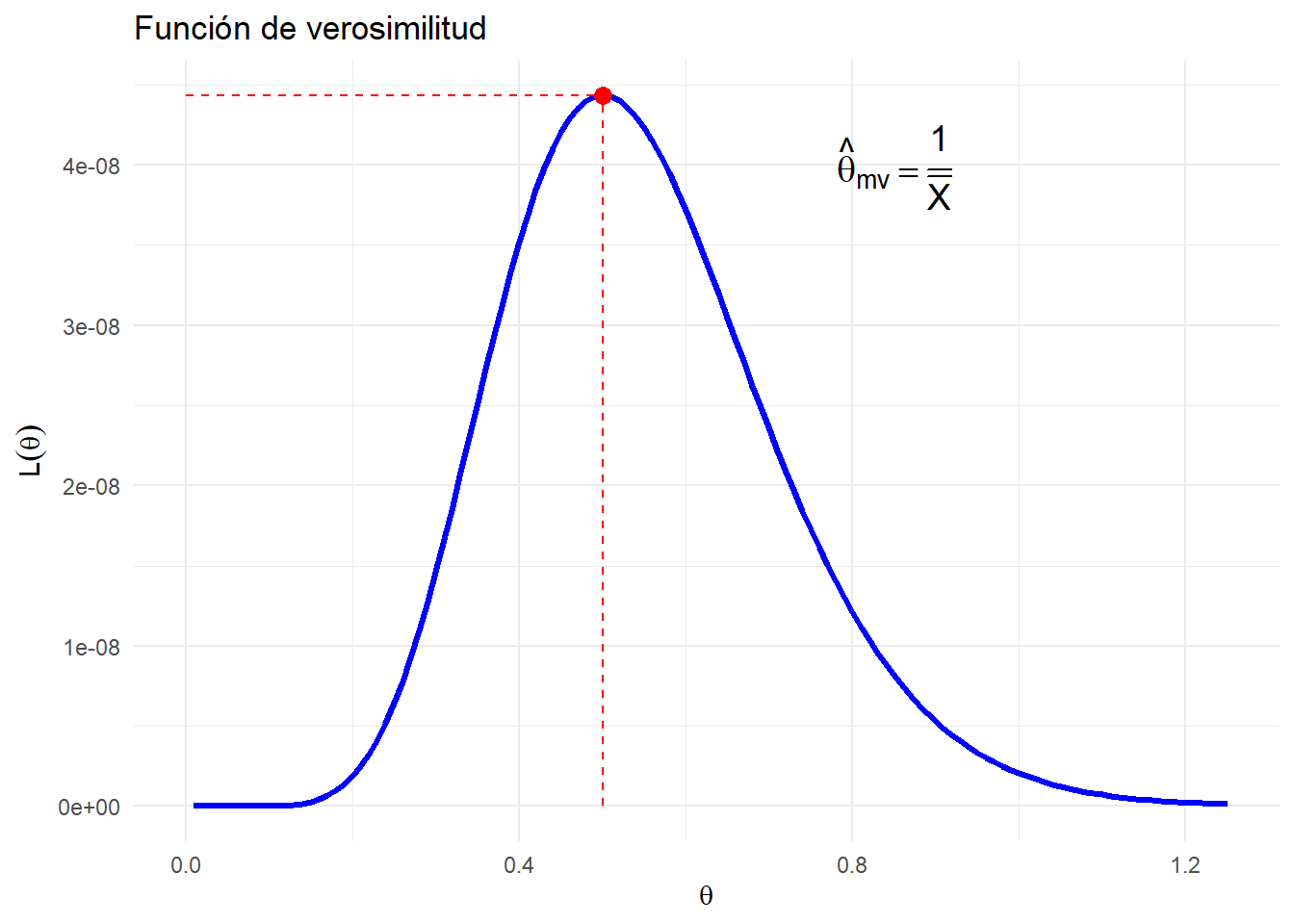
Ejemplo 3.1 Encontraremos la estimación de máxima verosimilitud del parámetro desconocio \(\theta\) de una distribución exponencial \(exp(\theta)\). Dada una muestra aleatoria de tamaño \(n\), \(X_1, X_2, \ldots, X_n\) de esta distribución, la función de verosimilitud para \(\theta>0\) es
theta <-seq(0.01, 1.25, by =0.01)n <-10media_x <-2df_ejemplo <-tibble(theta = theta,L = theta^n *exp(-theta * n * media_x))ggplot(df_ejemplo, aes(x = theta, y = L)) +geom_line(color ="blue", linewidth =1.2) +annotate("segment", x =1/media_x, xend =1/media_x, y =0, yend =max(df_ejemplo$L), linetype ="dashed", color ="red") +annotate("segment", x =0, xend =1/media_x, y =max(df_ejemplo$L), yend =max(df_ejemplo$L), linetype ="dashed", color ="red") +annotate("point", x =1/media_x, y =max(df_ejemplo$L), color ="red", size =3) +annotate("text", x =0.85, y =max(df_ejemplo$L) *0.9, label ="hat(theta)[mv] == frac(1, bar(X))", parse =TRUE, color ="black", size =5) +labs(title ="Función de verosimilitud",x =expression(theta),y =expression(L(theta))) +theme_minimal()
Maximizar la función \(L(\theta)\) es equivalente a maximizar su logaritmo, llamado log-verosimilitud, pues la función logaritmo es continua y monótona creciente en su dominio de definicion. Tenemos entonces que
Obsérvese que hemos escrito \(\hat{\theta}_{mv}\) en lugar de \(\theta_{mv}\) para indicar que se trata de un estimador, es decir, una variable aleatoria que depende de la muestra aleatoria \(X_1, X_2, \ldots, X_n\). Calculando la segunda derivada de la log-verosimilitud, se tiene que efectivamente se trata de un máximo local.
Si \(x_1, x_2, \ldots, x_n\) son los valores observados de la muestra aleatoria, entonces el número
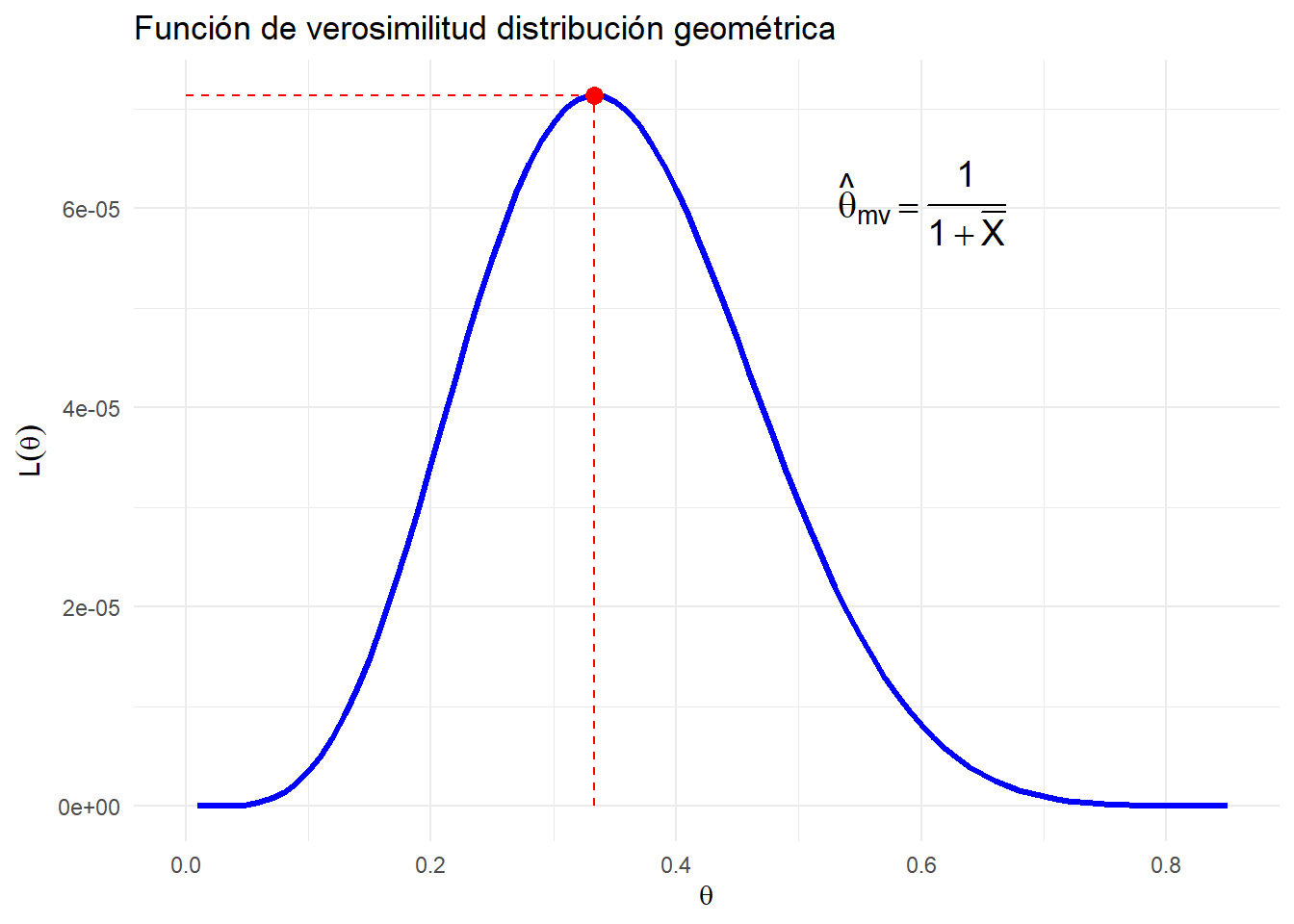
Ejemplo 3.2 Sea \(X_1, \dots, X_n\) una muestra aleatoria de una distribución geométrica \(geom(\theta)\), con parámetro \(\theta\) desconocido. La función de verosimitlitud, para \(\theta \in (0,1)\), es
Al calcular la segunda derivada de la log-verosimilitud, se tiene que efectivamente se trata de un máximo local en el espacio parametral \(\Theta = (0,1)\).
El método de máxima verosimilitud puede aplicarse a distribuciones con más de un parámetro desconocido. En este caso, la función de verosimilitud depende de varios parámetros y la maximización se realiza simultáneamente respecto a todos ellos. En el siguiente ejemplo se encuentras los estimadores máximos verosímiles de los parámetros de la distribución normal.
Ejemplo 3.3 Dada una muestra aleatoria de tamaño \(n\) de la distribución normal \(N(\mu, \sigma^2)\), en donde ambos parámetros son desconocidos \(\mu \in \mathbb{R}\) y \(\sigma > 0\), la función de verosimilitud es
Buscamos encontrar los valores de \(\mu\) y \(\sigma^2\) que maximizan la función de dos variables \(L(\mu, \sigma^2)\). Para ello, es más sencillo maximizar la log-verosimilitud, tenemos que
Se evalúa esta matriz en el punto crítico \((\hat{\mu}, \hat{\sigma}^2)\) y se comprueba que la matriz \(H(\hat{\mu}, \hat{\sigma}^2)\) es negativa definida, por lo que efectivamente se trata de un máximo local. Observemos que, para esta distribución, los estimadores por máxima verosimilitud coinciden con los estimadores encontrados por el método de los momentos. Esto no siempre ocurre.
Observación. Al aplicar las derivadas para encontrar el máximo de la función de verosimilitud no siempre produce expresiones cerradas para los estimadores. En estos casos, es necesario utilizar métodos numéricos para encontrar los valores que maximizan la función de verosimilitud. Por ejemplo, para la distribución \(\gamma(\gamma, \lambda)\), con ambos parámetros desconocidos, no es posible encontrar expresiones cerradas para los estimadores máximos verosímiles. En estos casos, se puede utilizar el método de Newton-Raphson para encontrar los valores que maximizan la función de verosimilitud.
Ahora, para la distribución \(binom(k, p)\), con ambos parámetros desconocidos, la dificultad radica en que el parámetro \(k\geq 1\) es entero y \(p\in (0,1)\), para cualquier tamaño de muestra \(n\). En este caso, se puede utilizar el método de máxima verosimilitud para encontrar el estimador de \(p\) en función de \(k\), y luego utilizar un método de búsqueda en cuadrícula para encontrar el valor de \(k\) que maximiza la función de verosimilitud.
3.2 Observaciones Generales
Después de haber mostrado algunos ejemplos del método de máxima verosimilitud, haremos ahora algunas observaciones generales sobre este método para estimar parámetros.
Aplicación. El método de máxima verosimilitud puede aplicarse a cualquier distribución de probabilidad, tanto discreta como continua.
Momentos vs Máxima Verosimilitud. El método de máxima verosimilitud no produce necesariamente los mismos estimadores que el método de momentos. Esto es así porque en cada método se busca el valor de \(\theta\) que satisface diferentes criterios. En el método de momentos, se busca el valor de \(\theta\) que iguala los momentos muestrales con los momentos poblacionales, mientras que en el método de máxima verosimilitud, se busca el valor de \(\theta\) que maximiza la función de verosimilitud.
Aplicación general. En los ejemplos mostrados, se aplicó el método de máxima verosimilitud a muestras aleatorias, por ello la función de verosimilitud se pudo expresar como el producto de las funciones de densidad o de probabilidad marginales. Sin embargo, el método de máxima verosimilitud es más general y puede aplicarse a cualquier colección de variables aleatorias, no necesariamente independientes ni idénticamente distribuidas.
Diferenciabilidad. El procedimiento usual de maximización de la función de verosimilitud a través del cálculo de derivadas puede llevarse a cabo únicamente cuando el parámetro \(\theta\) es continuo, la función de verosimilitud es diferenciable respecto a \(\theta\) y cuando ésta alcanza un máximo en el interior del espacio parametral \(\Theta\). Sin embargo, el método de máxima verosimilitud es más general y no presupone necesariamente el uso de derivadas par su aplicación. Por ejemplo, si un parámetro toma valores enteros, entonces se puede utilizar un método de búsqueda en cuadrícula para encontrar el valor que maximiza la función de verosimilitud.
Valores del parámetro. Suponiendo la existencia de un estimador máximo verosímil, y a diferencia del método de momentos, el método de máxima verosimilitud garantiza que la estimación obtenida toma un valor en el espacio parametral \(\Theta\). Esto es así por la especificación misma del método: se busca el valor del parámetro que maximiza la función de verosimilitud en el espacio parametral \(\Theta\).
Difeomorfismos. Como se ha mostrado en los ejemplos, en algunas ocasiones resulta más conveniente maximizar el logaritmo de la función de verosimilitud que la función de verosimilitud misma. En general, si \(g: \mathbb{R} \to \mathbb{R}\) es un difeomorfismo (función biyectiva, diferenciable y cuya inversa es diferenciable), entonces maximizar \(L(\theta)\) es equivalente a maximizar \(g(L(\theta))\). Esto puede ser útil en algunos casos para simplificar el proceso de maximización.
Existencia y unicidad. No siempre existe un estimador máximo verosímil, y cuando existe, no siempre es único. Por ejemplo, si la función de verosimilitud es constante respecto a \(\theta\), entonces cualquier valor en el espacio parametral \(\Theta\) es una estimación de máxima verosimilitud. En otros casos la función de verosimilitud puede tener varios máximos locales, lo que lleva a múltiples estimaciones de máxima verosimilitud. En la práctica, estos problemas suelen ser poco comunes, pero es importante tenerlos en cuenta.
Cambios en el espacio parametral. Si se reduce el espacio parametral \(\Theta\), es decir, si se reduce el dominio de definición de la función de verosimilitud, es muy posible que el máximo de la función de verosimilitud cambie, y por lo tanto, el estimador máximo verosímil también cambie. Por ejemplo, si se añade una restricción al parámetro \(\theta\) que lo obliga a tomar valores en un subconjunto más pequeño de \(\Theta\).