| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| (D) Dado | 0 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
| (M) Moneda | 1/32 | 5/32 | 10/32 | 10/32 | 5/32 | 1/32 | 0 |
6 Pruebas de hipótesis
Nota: El contenido de esta sección es una adaptación al formato Quarto del capítulo 4 del libro Introducción a la Estadística Inferencial de Luis Rincón (2019).
Se brindará una introducción al tema de pruebas de hipótesis. Inicialmente nos enfocaremos en la estimación de parámetros de las distribuciones de probabilidad.
6.1 Introducción
Se ilustrarán las ideas básicas de una prueba de hipótesis mediante un ejemplo sencillo. Posteriormente se formalizarán los respectivos conceptos.
Consideraremos una situación en la que se efectúa sólo uno de los siguientes experimentos aleatorios: se lanza un dado equilibrado y se registra el número obtenido, o bien, se lanza una moneda cinco veces y se registra el número de caras obtenidas.
El problema radica en que únicamente conocemos el resultado \(x\) del experimento y no se conoce el experimento aleatorio efectuado. Deseamos determinar cuál de los dos experimentos se realizó con base en el número \(x\) observado.
Tenemos entonces una situación de dos hipótesis posibles:
Hipótesis nula \(H_0\): se lanzó el dado equilibrado.
Hipótesis alternativa \(H_1\): se lanzó la moneda cinco veces.
Como única información tenemos un número \(x\in \{0,1,2,3,4,5,6\}\) y con base en este se debe decidir cuál de los experimentos aleatorios se realizó. Inicialmente notemos que:
Si \(x=0\) con seguridad se puede afirmar que se lanzó la moneda cinco veces, ya que el dado equilibrado no puede arrojar un cero.
Si \(x=6\) con seguridad se puede afirmar que se lanzó el dado equilibrado, ya que la moneda lanzada cinco veces no puede arrojar seis caras.
Si \(x\in \{1,2,3,4,5\}\) no se puede afirmar con seguridad cuál de los dos experimentos se realizó, ya que ambos pueden arrojar esos resultados.
Para decidir cuál de las dos hipótesis es más plausible, se puede considerar la probabilidad de observar el resultado \(x\) bajo cada una de las hipótesis (máxima verosimilitud). Tales probabilidades se muestran enl a siguiente tabla, donde, para cada valor de \(x\) se indica el caso con mayor probabilidad:
Cabe señalar que para los lanzamientos de la moneda se trata de una variable aleatoria \(X\sim \text{bin}(5, 1/2)\) donde la probabilidad para los posibles valores \(x= 0, 1, 2, 3, 4, 5\) está dada por \[f(x) = P(X=x) = \binom{5}{x} \left(\frac{1}{2}\right)^x \left(\frac{1}{2}\right)^{5-x} = \binom{5}{x}\frac{1}{32}.\] Siguiendo el criterio de máxima verosimilitud, se decide a favor de la hipótesis que asigna mayor probabilidad al resultado observado \(x\). Resultando la siguiente regla de decisión:
Al conjunto \(\mathscr{C}\) se le denomina región crítica o región de rechazo de la hipótesis nula \(H_0\). Notemos que esta regla de decisión no está exenta de errores, por ejemplo, si \(x=2\), se decide por el experimento de la moneda, pero el resultado bien pudo provenir del dado. Por otro lado, si \(x=1\), se decide por el dado pero es factible que el resultado haya sido obtenido por la moneda.
Los dos tipos de errores que se pueden presentar se denominan error tipo I y error tipo II, y se muestran en la siguiente tabla:
| Decisión | \(H_0\) verdadera | \(H_0\) falsa |
|---|---|---|
| Rechazar \(H_0\) | Error tipo I | Correcto |
| No rechazar \(H_0\) | Correcto | Error tipo II |
Se usan las letras \(\alpha\) y \(\beta\) para denotar a las probabilidades de cometer un error tipo I y un error tipo II, respectivamente. Cada uno de estos errores se definen y calculan como las siguientes probabilidades condicionales:
\[\begin{eqnarray} \alpha & = & P(\text{Rechazar } H_0 \mid H_0 \text{ es verdadera}) = P(X \in \mathscr{C} \mid H_0 \text{ verdadera}) \\ \beta & = & P(\text{No rechazar } H_0 \mid H_0 \text{ es falsa}) = P(X \in \mathscr{C}^c \mid H_0 \text{ falsa}) \end{eqnarray}\]
El tratamiento que se les da a estas probabilidades condicionales no es el usual de la probabilidad elemental, pues no tenemos la información para calcular la probabilidad de los eventos condicionantes. Supondremos que \(H_0\) es cierta (en el caso para calcular \(\alpha\)) o falsa (en el caso para \(\beta\)), y en cada situación veremos si la información supuesta es suficiente para calcular estas probabilidades.
Para el ejemplo del dado y la moneda, las probabilidades de estos errores se calculan de la siguiente manera: suponiendo que el número reportado es una variable aleatoria \(X\), \(D\) denotal al evento de lanzar el dado y \(M\) el evento de lanzar la moneda, entonces
\[\begin{eqnarray} \alpha & = & P(\text{Error tipo I})\\ & = & P(\text{Rechazar } H_0 \mid H_0 \text{ es verdadera}) \\ & = & P(X \in \{0, 2,3\} \mid D) \\ & = & 2/6 = 1/3 \end{eqnarray}\]
Por otro lado,
\[\begin{eqnarray} \beta & = & P(\text{Error tipo II})\\ & = & P(\text{No rechazar } H_0 \mid H_0 \text{ es falsa}) \\ & = & P(X \in \{1,4,5,6\} \mid M) \\ & = & 11/32 \end{eqnarray}\]
Observemos que estas probabilidades no suman 1 pues los eventos condicionantes son distintos. Por otro lado, se requiere que estas probabilidades de error sean lo más pequeñas posibles. Sin embargo, existe una relación inversa entre ambas: si se disminuye una, la otra aumenta. Por ejemplo, si se desea disminuir la probabilidad de cometer un error tipo I, se puede reducir la región crítica \(\mathscr{C}\), pero al hacerlo se incrementa la probabilidad de cometer un error tipo II.
Veamos algunos ejemplos para ilustrar esos posibles comportamientos. Tomaremos como referencia la región de rechazo \(\mathscr{C} = \{0,2,3\}\) en donde hemos obtenido \(\alpha=1/3\) y \(\beta=11/32\).
Si se toma la región de rechazo \(\mathscr{C} = \{0,1,2,3\}\), entonces
\[\begin{eqnarray} \alpha & = & P(\text{Error tipo I}) \\ & = & P(X\in \{0, 1, 2, 3\} \mid D)\\ & = & 3/6 \end{eqnarray}\]
\[\begin{eqnarray} \beta & = & P(\text{Error tipo II}) \\ & = & P(X \in \{4,5,6\} \mid M) \\ & = & 6/32 \end{eqnarray}\]
Observamos que al aumentar la región crítica, se incrementa la probabilidad \(\alpha\) de cometer un error tipo I, pero se disminuye la probabilidad \(\beta\) de cometer un error tipo II. Comparativamente no podemos decir que una región de rechazo sea mejor que la otra, a menos que fijemos prioridades en los dos tipos de error.
Si se toma la región de rechazo \(\mathscr{C} = \{2,3\}\), entonces
\[\begin{eqnarray} \alpha & = & P(\text{Error tipo I}) \\ & = & P(X\in \{2, 3\} \mid D)\\ & = & 2/6 \end{eqnarray}\]
\[\begin{eqnarray} \beta & = & P(\text{Error tipo II}) \\ & = & P(X \in \{0, 1, 4,5,6\} \mid M) \\ & = & 12/32 \end{eqnarray}\]
En este caso \(\alpha\) permanece sin cambio, pero \(\beta\) aumenta. Comparativamente, la región de rechazo \(\mathscr{C} = \{0,2,3\}\) es mejor que \(\mathscr{C} = \{2,3\}\).
En general, dos regiones de rechazo pueden no ser comparables desde el punto de vista de las probabilidades de error, pues un tipo de error puede ser menor para una región de rechazo y el otro tipo de error puede ser mayor. En términos generales, seguiremos el siguiente criterio para la comparación de dos regiones de rechazo cuando sea posible:
En la siguiente tabla se muestran distintas regiones de rechazo \(\mathscr{C}\) con el mismo valor \(\alpha = 2/6\) y para las cuales se ha calculado la probabilidad \(\beta\). Se indica la región de rechazo que minimiza la probabilidad \(\beta\).
| Región de rechazo | \(\alpha\) | \(\beta\) |
|---|---|---|
| \(\mathscr{C} = \{0, 1, 2\}\) | 2/6 | 16/32 |
| \(\mathscr{C} = \{0, 1, 3\}\) | 2/6 | 16/32 |
| \(\mathscr{C} = \{0, 1, 4\}\) | 2/6 | 21/32 |
| \(\mathscr{C} = \{0, 1, 5\}\) | 2/6 | 25/32 |
| \(\mathscr{C} = \{0, 1, 6\}\) | 2/6 | 26/32 |
| \(\mathscr{C} = \{0, 2, 3\}\) | 2/6 | 11/32 |
| \(\mathscr{C} = \{0, 2, 4\}\) | 2/6 | 16/32 |
| \(\mathscr{C} = \{0, 2, 5\}\) | 2/6 | 20/32 |
| \(\mathscr{C} = \{0, 2, 6\}\) | 2/6 | 21/32 |
| \(\mathscr{C} = \{0, 3, 4\}\) | 2/6 | 16/32 |
| \(\mathscr{C} = \{0, 3, 5\}\) | 2/6 | 20/32 |
| \(\mathscr{C} = \{0, 3, 6\}\) | 2/6 | 21/32 |
| \(\mathscr{C} = \{0, 4, 5\}\) | 2/6 | 25/32 |
| \(\mathscr{C} = \{0, 4, 6\}\) | 2/6 | 26/32 |
| \(\mathscr{C} = \{0, 5, 6\}\) | 2/6 | 30/32 |
6.2 Conceptos elementales
En esta sección se formalizan los conceptos elementales de las pruebas de hipótesis, algunos de ellos mencionados en la sección anterior. Se estudian pruebas de hipótesis principalmente en el contexto de la estimación de parámetros en las distribuciones de probabilidad. A tales pruebas se les denomina pruebas paramétricas. A continuación se brinda la definición de hipótesis estadística.
Definición 6.1 Una hipótesis estadística, o simplemente hipótesis, es una afirmación o conjetura acerca de la distribución de una o más variables aleatorias.
Particularmente las hipótesis a las que se hará referencia serán afirmaciones o conjeturas acerca del valor de los parámetros de las distribuciones de probabilidad.
Establecer con precisión las hipótesis a contrastar depende fuertemente del estudio que se esté llevando a cabo, de la pregunta que se desea contestar y de la información adicional que se tenga acerca del problema particular en estudio. Nuestra perspectiva será que las hipótesis a contrastar son dadas, o que son evidentes de proponer de acuerdo al enunciado del problema.
La siguiente definición establece una clasificación de dos tipos generales de hipótesis que pueden considerarse relativas a la especificación de los parámetros de una distribución.
Definición 6.2 Una hipótesis estadística es simple si especifica por completo la distribución de probabilidad en cuestión, en caso contrario, la hipótesis se denomina compuesta.
En general, contrastaremos dos hipótesis estadísticas, de acuerdo al siguiente esquema y notación:
\(H_0\): Hipótesis nula o hipótesis de referencia. vs \(H_1\): Hipótesis alternativa o hipótesis de investigación.
Tanto la hipótesis nula \(H_0\) como la hipótesis alternativa \(H_1\) pueden ser simples o compuestas. De este modo tenemos cuatro diferentes contrastes de tipo de hipótesis: simple vs simple, simple vs compuesta, compuesta vs simple y compuesta vs compuesta. Las tres últimas son más difíciles de analizar.
Llevar a cabo una prueba de hipótesis significa aplicar una regla para decidir si se acepta la hipótesis nula o se rechaza en favor de la hipótesis alternativa. La información para obtener una regla de decisión que nos lleve a rechazar o no rechazar una hipótesis estadística provendrá de una muestra aleatoria de la distribución en estudio. Por otro lado, al aceptar una hipótesis no se afirma que ésta sea absolutamente cierta, sino simplemente que es consistente con los datos de la muestra aleatoria y la regla de decisión adoptada. Si la información de la muestra o la regla de decisión cambia, muy posiblemente también cambie la decisión de rechazar o no rechazar.
La regla para decidir si se acepta la hipótesis nula o se rechaza en favor de la hipótesis alternativa se expresa en términos de un conjunto llamado región de rechazo. Este conjunto consta de aquellos valores de la muestra aleatoria para los cuales se ha acordado rechazar la hipótesis nula. Es claro que existen tantas regiones de rechazo como subconjuntos de valores de la muestra aleatoria.
Definición 6.3 Una región de rechazo es un subconjunto de valores de la muestra aleatoria para los cuales se decide rechazar la hipótesis nula \(H_0\). A una región de rechazo se le llama también región crítica.
Desde el punto de vista matemático, uno de los problemas principales en las pruebas de hipótesis es el de construir de manera justificada una región de rechazo. Con base en la región de rechazo encontrada se puede entonces llevar a cabo el proceso de decisión de rechazar o no rechazar la hipótesis nula.
Como se mencionó antes, al tomar una decisión en una prueba de hipótesis, existe siempre el riesgo de cometer errores. Los dos tipos de errores que pueden surgir se formalizan en las siguientes dos definiciones.
Definición 6.4 El error tipo I se comete cuando se rechaza la hipótesis nula \(H_0\) cuando ésta es verdadera. A la probabilidad de cometer el error tipo I se le denota por la letra \(\alpha\), y se calcula mediante la siguiente probabilidad condicional:
\[\begin{eqnarray} \alpha & = & P(\text{Error tipo I}) \\ & = & P(\text{Rechazar } H_0 \mid H_0 \text{ es verdadera}). \end{eqnarray}\]
A este valor \(\alpha\) se le conoce también como el tamaño de la región crítica, el tamaño de la región de rechazo, o bien como el nivel de significancia de la prueba.
Definición 6.5 El error tipo II se comete cuando no se rechaza la hipótesis nula \(H_0\) cuando ésta es falsa. A la probabilidad de cometer el error tipo II se le denota por la letra \(\beta\), y se calcula mediante la siguiente probabilidad condicional:
\[\begin{eqnarray} \beta & = & P(\text{Error tipo II}) \\ & = & P(\text{No rechazar } H_0 \mid H_0 \text{ es falsa}). \end{eqnarray}\]
Las probabilidades \(\alpha\) y \(\beta\) no son complementarias, es decir, no necesariamente se cumple que \(\alpha + \beta = 1\), pues los eventos condicionantes son distintos. En general, se desea que ambas probabilidades sean lo más pequeñas posibles, aunque existe una relación inversa entre ambas: si se disminuye una, la otra aumenta. Por ejemplo, si se desea disminuir la probabilidad de cometer un error tipo I, se puede reducir la región crítica, pero al hacerlo se incrementa la probabilidad de cometer un error tipo II.
Cuando sea posible, se procederá de la siguiente manera: se fija un valor para \(\alpha\) y se busca aquella posible región de rechazo de tamaño \(\alpha\) que tenga probabilidad \(\beta\) más pequeña. De esta manera se le da mayor importancia al error del tipo I pues se controla su probabilidad de ocurrencia.
Observemos que si \(H_0\) es una hipótesis simple, entonces la distribución de probabilidad en estudio queda completamente especificada y la probabilidad \(\alpha\) podrá ser calculada de manera exacta, aunque en ocasiones puede usarse una aproximación con el fin de dar una expresión corta para esta cantidad. En cambio, si \(H_0\) es una hipótesis compuesta, entonces no podrá calcularse \(\alpha\) pues en tales situaciones se desconoce el valor exacto del parámetro o parámetros en estudio. La misma situación ocurre para \(\beta\) cuando \(H_1\) es simple o compuesta, únicamente en el caso cuando \(H_1\) es simple se puede calcular el valor de \(\beta\) de manera exacta.
Suponiendo el caso del contraste de dos hipótesis simples, un problema consiste en considerar todas las posibles regiones de rechazo de tamaño \(\alpha\) y encontrar aquella que tenga probabilidad \(\beta\) más pequeña. Es claro que el interés es encontrar este tipo de regiones de rechazo óptimas y la solución a este problema es el contenido del así llamado lema de Neyman-Pearson que estudiaremos más adelante.
6.3 Función potencia
Establecida una región de rechazo para una prueba de hipótesis, la función potencia se define como la probabilidad de rechazar la hipótesis nula \(H_0\) para cada posible valor del parámetro \(\theta\). Esto es lo que significa la notación un tanto ambigua de la probabilidad condicional que aparece en la siguiente definición.
Definición 6.6 Suponiendo dada una región de rechazo, la función potencia de una prueba de hipótesis sobre un parámetro desconocido \(\theta\) es la función definida por
\[\theta \mapsto \pi(\theta) = P(\text{Rechazar } H_0\mid \theta).\]
Por lo tanto, la función potencia está definida en cada punto del espacio parametral correspondiente. Esta función puede ser útil para comparar dos regiones de rechazo. Cuando se contrastan dos hipótesis simples \(H_0: \theta = \theta_0\) vs \(H_1: \theta=\theta_1\), las dos probabilidades de error se pueden expresar en términos de la funión potencia como sigue
\[\begin{eqnarray} \alpha & = & P(\text{Rechazar } H_0 \mid \theta = \theta_0) = \pi(\theta_0) \\ \beta & = & P(\text{No rechazar } H_0 \mid \theta = \theta_1) = 1 - \pi(\theta_1) \end{eqnarray}\]
A continuación se presenta un ejemplo para ilustrar el cálculo de la función potencia.
Ejemplo 6.1 Consideremos el contraste de hipótesis simples
\[H_0: \theta = \theta_0 \quad vs \quad H_1: \theta = \theta_1,\]
en donde \(\theta_0<\theta_1\) son dos valores fijos del parámetro desconocido \(\theta\) de una distribución Bernoulli. Debido a que la media de una muestra aleatoria de esta distribución se acerca al valor del parámetro cuando el tamaño de la muestra tiende a infinito, convengamos en adoptar como región de rechazo el conjunto \[\mathscr{C} = \left\{ (x_1, \dots, x_n)\mid \overline{x}\geq (\theta_0+\theta_1)/2 \right\},\]
en donde \((\theta_0 + \theta_1)/2\) es el punto medio del intervalo con extremo izquierdo \(\theta_0\) y extremo derecho \(\theta_1\). De esta manera, si la media muestral se separa de \(\theta_0\) hacia la derecha a partir del punto \((\theta_0 + \theta_1)/2\) en adelante, se decide rechazar la hipótesis nula \(H_0\) en favor de la hipótesis alternativa \(H_1\).
Teniendo definida esta región de rechazo, podemos ahora calcular de manera aproximada las probabilidades de los errores tipo I y II, y más generalmente la función potencia de la siguiente forma: por el teorema central del límite
\[\begin{eqnarray} \alpha & = & P(\overline{X}\geq (\theta_0 + \theta_1)/2 \mid \theta = \theta_0) \\ & = & P\left(\frac{\overline{X}-\theta_0}{\sqrt{\theta_0(1-\theta_0)/n}} \geq \frac{(\theta_1-\theta_0)/2}{\sqrt{\theta_0(1-\theta_0)/n}} \mid \theta = \theta_0 \right)\\ & \approx & 1 - \Phi\left( \frac{(\theta_1-\theta_0)/2}{\sqrt{\theta_0(1-\theta_0)/n}} \right) \end{eqnarray}\]
\[\begin{eqnarray} \beta & = & P(\overline{X} < (\theta_0 + \theta_1)/2 \mid \theta = \theta_1) \\ & = & P\left(\frac{\overline{X}-\theta_1}{\sqrt{\theta_1(1-\theta_1)/n}} < \frac{(\theta_0-\theta_1)/2}{\sqrt{\theta_1(1-\theta_1)/n}} \mid \theta = \theta_1 \right) \\ & \approx & \Phi\left( \frac{(\theta_0-\theta_1)/2}{\sqrt{\theta_1(1-\theta_1)/n}} \right) \end{eqnarray}\]
Recordemos que los valores de \(\theta_0\), \(\theta_1\) y \(n\) son conocidos y, por lo tanto, las cantidades anteriores pueden calcularse explícitamente. Usando nuevamente el teorema central del límite, la función potencia se puede aproximar de la siguiente manera: para \(\theta \in (0,1)\)
\[\begin{eqnarray} \pi(\theta) & = & P(\overline{X} \geq (\theta_0 + \theta_1)/2 \mid \theta) \\ & = & P\left(\frac{\overline{X}-\theta}{\sqrt{\theta(1-\theta)/n}} \geq \frac{(\theta_0 + \theta_1)/2 - \theta}{\sqrt{\theta(1-\theta)/n}} \mid \theta \right) \\ & \approx & 1 - \Phi\left( \frac{(\theta_0 + \theta_1)/2 - \theta}{\sqrt{\theta(1-\theta)/n}} \right) \end{eqnarray}\]
Haciendo un análisis cualitativo del comportamiento de esta función para valores de \(\theta\) cercanos a cero y a uno, se puede comprobar que la gráfica de esta función es la curva creciente que se muestra a continuación.
Código
theta_0 <- 0.3
theta_1 <- 0.7
n <- 10
theta_vals <- seq(0, 1, by = 0.005)
pi_vals <- 1 - pnorm(((theta_0 + theta_1) / 2 - theta_vals) / sqrt(theta_vals * (1 - theta_vals) / n))
alpha <- 1 - pnorm(((theta_1 - theta_0) / 2) / sqrt(theta_0 * (1 - theta_0) / n))
beta <- pnorm((-(theta_1 - theta_0) / 2) / sqrt(theta_1 * (1 - theta_1) / n))
ggplot(data.frame(theta = theta_vals, pi = pi_vals), aes(x = theta, y = pi)) +
geom_line(color = "dodgerblue4", linewidth = 1.3) +
annotate("segment", x = theta_0, xend = theta_0, y = 0, yend = alpha, color = "red", linetype = "dashed") +
annotate("segment", x = 0, xend = theta_0, y = alpha, yend = alpha, color = "red", linetype = "dashed") +
annotate("segment", x = theta_1, xend = theta_1, y = 0, yend = 1 - beta, color = "olivedrab", linetype = "dashed") +
annotate("segment", x = 0, xend = theta_1, y = 1 - beta, yend = 1 - beta, color = "olivedrab", linetype = "dashed") +
annotate("label", x = 0, y = alpha, label = "alpha", color = "black", parse = TRUE) +
annotate("label", x = 0, y = 1 - beta, label = "1 - beta", color = "black", parse =TRUE) +
annotate("label", x = theta_0, y = -0.07, label = "theta[0]", color = "black", parse =TRUE) +
annotate("label", x = theta_1, y = -0.07, label = "theta[1]", color = "black", parse = TRUE) +
labs(x = expression(theta),
y = expression(pi(theta))) +
theme_minimal()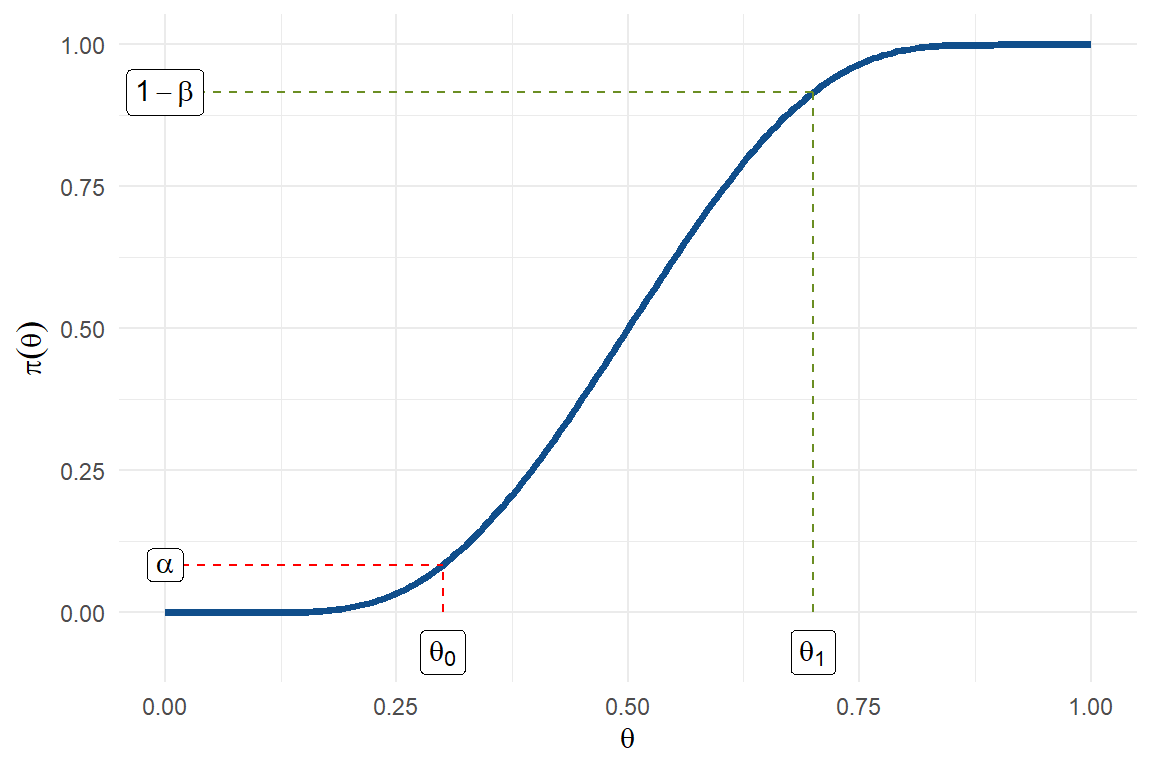
Esta es la función potencia asociada a la región de rechazo especificada. Esta función toma el valor \(\alpha\) cuando \(\theta=\theta_0\) y toma el valor \(1-\beta\) en \(\theta = \theta_1\). En general, para valores de \(\theta\) alrededor de \(\theta_0\) la probabilidad de rechazar la hipótesis nula es baja. En cambio, para valores de \(\theta\) cercanos a \(\theta_1\) la probabilidad de rechazar es alta dando preferencia a este valor del parámetro.
6.4 Ejemplo de una prueba paramétrica
A continuación se desarrolla otro ejemplo en donde se ilustran los conceptos generales y el procedimiento para llevar a cabo una prueba de hipótesis. Esta vez nos referiremos a hipótesis relativas al valor de un paramétro de una distribución.
Consideremos una población dada en la cual se observa una proporción de elementos que poseen cierta característica y que puede modelarse mediante una variable aleatoria \(X\) con distribución Bernoulli. Supongamos que se plantea la hipótesis que la proporción de personas en la población con dicha característica es \(0.5\). Si se lleva a cabo un muestreo de \(n=100\) y \(49\) personas tienen la característica de interés, se puede pensar que es evidencia para corroborar que la proporción es de \(0.5\). Pero, si en otros muestreos la cantidad de personas con la característica es de \(40\) o de \(60\), ¿se podría decidir que la proporción hipotética de \(0.5\) es correcta? En estos últimos casos la decisión no es tan evidente. Ahora se plantea y resuelve este problema de decisión a través del contraste de dos hipótesis.
Denotemos por \(X_1, X_2, \dots, X_n\) a una muestra aleatoria de tamaño \(n\) y definimos
\[\begin{equation} X_i = \begin{cases} 1 & \text{si la i-ésima persona tiene la característica} \\ 0 & \text{si la i-ésima persona no tiene la característica} \end{cases} \end{equation}\]
Es decir, cada una de estas variables tiene distribución Bernoulli de parámetro \(\theta\), en donde este parámetro es la probabilidad desconocida de que alguna persona en la población posea la característica de interés. El problema planteado se formaliza y traduce en llevar a cabo la siguiente prueba de hipótesis
\[H_0: \theta = 1/2 \quad vs \quad H_1: \theta \neq 1/2.\]
Se observa que la hipótesis nula \(H_0\) es simple, mientras que la hipótesis alternativa \(H_1\) es compuesta. A continuación se construye una región de rechazo para esta prueba. Por la ley de los grandes números, la media muestral \(\overline{X}\) se acerca al valor verdadero \(\theta\) cuando el tamaño de la muestra es cada vez más grande, y por lo tanto, es una aproximación para el valor desconocido de \(\theta\). Cuando \(\overline{X}\) diste mucho de \(1/2\) es razonable pensar que la característica de interés no es equilibrada. Es por ello que se propone rechazar la hipótesis \(H_0\) cuando \(|\overline{X}-1/2|\geq c\), para algún número \(c\) que se encontrará posteriormente, y eso se hará estableciendo un valor particular para la probabilidad del error tipo I. Es decir, se propone como región de rechazo al conjunto
\[\mathscr{C} = \{ (x_1, x_2, \dots, x_n) \mid |\overline{x} - 1/2| \geq c \}.\] En el caso cuando \(H_0\) es cierta, pero se toma la decisión de rechazarla, se está en la situación de cometer el error tipo I, y establecemos que la probabilidad de que ello ocurra es \(\alpha\), es decir,
\[\begin{eqnarray} \alpha & = & P(\text{Error tipo I}) \\ & = & P(\text{Rechazar } H_0 \mid H_0 \text{ es verdadera}) \\ & = & P(|\overline{X} - 1/2| \geq c \mid \theta = 1/2). \end{eqnarray}\]
A partir de la última expresión se puede encontrar el valor de \(c\) de la siguiente manera: cuando \(H_0\) es verdadera, es decir, cuando \(\theta=1/2\), la media muestral tiene distribución aproximada normal con media \(1/2\) y varianza \((1/2)(1-1/2)/n=1/(4n)\), y por lo tanto, de manera aproximada \[\frac{\overline{X}-1/2}{1/(2\sqrt{n})} \sim N(0,1).\] Usando esta aproximación, se tiene que
\[\begin{eqnarray} \alpha & = & P(|\overline{X} - 1/2| \geq c \mid \theta = 1/2) \\ & = & 1 - P(|\overline{X} - 1/2| < c \mid \theta = 1/2) \\ & = & 1 - P\left( -c < \overline{X} - 1/2 < c \mid \theta = 1/2 \right) \\ & = & 1 - P\left( \frac{-c}{1/(2\sqrt{n})} < \frac{\overline{X} - 1/2}{1/(2\sqrt{n})} < \frac{c}{1/(2\sqrt{n})} \mid \theta = 1/2 \right) \\ & \approx & 2\left[ 1 - \Phi\left( \frac{c}{1/(2\sqrt{n})} \right) \right] \end{eqnarray}\]
De la última expresión se obtiene que \[c \approx \frac{1}{2\sqrt{n}} \Phi^{-1}\left( 1 - \frac{\alpha}{2} \right).\] Así, dado un valor para el tamaño de muestra \(n\) y un valor convenido para \(\alpha\), este es el valor de la constante \(c\) que hace que la región de rechazo \(\mathscr{C}\) sea de tamaño \(\alpha\). Por ejemplo para \(n = 100\) y \(\alpha=0.01\) se tiene:
Código
n <- 100
alpha <- 0.01
c <- (1 / (2 * sqrt(n))) * qnorm(1 - alpha / 2)
cat("El valor de c es:", round(c,5), "\n")El valor de c es: 0.12879 Por otro lado, cuando \(n\) crece, la constante \(c\) disminuye y ello hace que el área de la región de rechazo disminuya, y por lo tanto la probabilidad \(\alpha\) disminuye. Como función de la probabilidad \(\alpha\), la constante \(c\) se comporta como se muestra en la siguiente gráfica.
Código
alpha_vals <- seq(0, 1, by = 0.001)
c_vals <- (1 / (2 * sqrt(n))) * qnorm(1 - alpha_vals / 2)
ggplot(data.frame(alpha = alpha_vals, c = c_vals), aes(x = alpha, y = c)) +
geom_line(color = "darkorange3", linewidth = 1.3) +
labs(x = expression(alpha),
y = expression(c)) +
theme_minimal()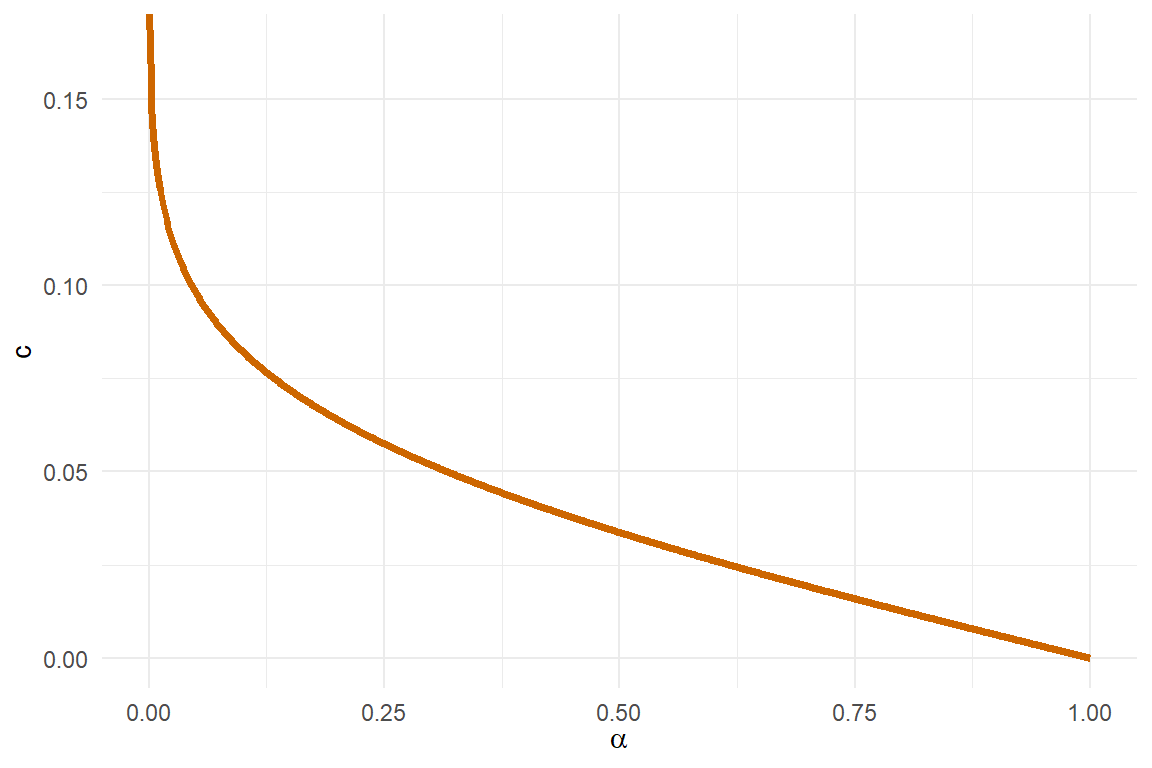
De esta forma la estadística de la prueba es la variable aleatoria \(\overline{X}\) y su valor determina el resultado de la prueba, si \[|\overline{X} - 1/2| \geq 0.12879,\] se rechaza la hipótesis nula \(H_0\); en caso contrario, no se rechaza \(H_0\). Esta región de rechazo, referida a \(\overline{X}\), se puede escribir como la unión de intervalos \[\mathscr{C} = [0, 1/2 - c] \cup [1/2 + c, 1],\]
como se muestra gráficamente en la siguiente figura.
Código
library(ggplot2)
library(ggtext)
# Definir el valor de c para el ejemplo
c_val <- 0.25
# Crear datos para la línea horizontal
line_data <- data.frame(
x = c(0, 1),
y = c(0, 0)
)
# Puntos importantes en el eje y etiquetas
points_data <- data.frame(
x = c(0, 0.5 - c_val, 0.5, 0.5 + c_val, 1),
y = rep(0, 5),
labels = c("0", "1/2 - c", "1/2", "1/2 + c", "1")
)
# Datos para la región de rechazo (curva)
curve_x <- seq(0.5 - c_val, 0.5 + c_val, length.out = 100)
curve_y <- 0.3 * exp(-50 * (curve_x - 0.5)^2) + 0.05
curve_data <- data.frame(
x = curve_x,
y = curve_y
)
# Crear el gráfico
p <- ggplot() +
# Línea horizontal principal
geom_line(data = line_data, aes(x = x, y = y),
linewidth = 1, color = "black") +
# Puntos en el eje
geom_point(data = points_data, aes(x = x, y = y),
size = 3, color = "black") +
# Líneas verticales cortas en los puntos
geom_segment(data = points_data,
aes(x = x, xend = x, y = -0.02, yend = 0.02),
color = "black", linewidth = 0.8) +
# Región de rechazo (curva)
geom_area(data = curve_data, aes(x = x, y = y),
fill = "lightblue", alpha = 0.6, color = "blue", linewidth = 1) +
# Región rechazo línea
geom_line(data = points_data[1:2, ], aes(x = x, y = y),
color = "firebrick", linewidth = 2) +
geom_line(data = points_data[4:5, ], aes(x = x, y = y),
color = "firebrick", linewidth = 2) +
# Etiquetas de los puntos
geom_text(data = points_data, aes(x = x, y = y, label = labels),
vjust = 2.5, size = 4, color = "black") +
# Texto "Rechazar H₀"
annotate("label", x = 0.5, y = 0.15, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
# Flechas apuntando a la región
annotate("curve", x = 0.3, y = 0.15, xend = 0.1, yend = 0.01,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0.3, color = "darkblue") +
annotate("curve", x = 0.7, y = 0.15, xend = 0.9, yend = 0.01,
arrow = arrow(length = unit(0.02, "npc")),
curvature = -0.3, color = "darkblue") +
# Personalización del tema
theme_minimal() +
theme(
axis.title = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
panel.grid = element_blank(),
axis.line.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
plot.margin = margin(20, 20, 20, 20)
) +
# Límites y escalas
xlim(-0.1, 1.1) +
ylim(-0.1, 0.4) +
# Coordenadas fijas para mantener proporción
coord_fixed(ratio = 2)
# Mostrar el gráfico
print(p)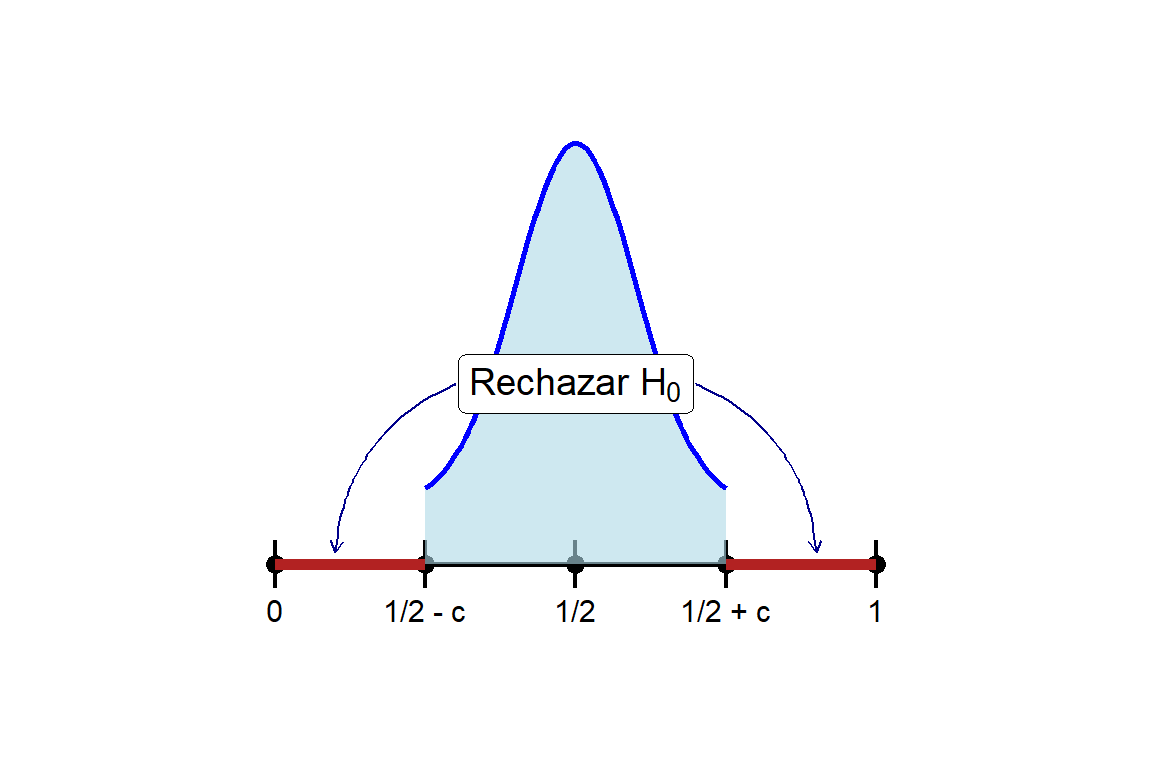
De esta manera, si \(\overline{X}\) es menor que o igual a \(1/2 - c\), o mayor que o igual a \(1/2 + c\), decidimos que la diferencia entre \(\overline{X}\) y \(1/2\) no es debido al azar y por lo tanto rechazamos la hipótesis nula \(H_0\). La probabilidad de un error al tomar tal decisión es \(\alpha\), de modo que se está tomando un riesgo del \(100\alpha\%\) de clasificar una característica equilibrada como no equilibrada.
De manera equivalente podemos expresar la región de rechazo en términos del número de personas con la característica de interés en una muestra. Considerando \(n=100\) y \(\alpha = 0.01\), al multiplicar por este valor de \(n\) la condición de rechazo \(|\overline{X}-1/2| \geq 0.128\) se obtiene la condición equivalente \[\left|\sum_{i=1}^{100}X_i - 50\right| \geq 12.8,\]
en donde la suma indicada es el número de personas en la muestra con la característica de interés. Es decir, cuando el número de personas difiera de 50 en más de 12.8, se rechaza la hipótesis nula.
Por otro lado, observemos que no se puede calcula la probabilidad del error tipo II, pues la hipótesis alternativa es compuesta y por lo tanto no se conoce el valor del parámetro \(\theta\) cuando \(H_0\) es falsa. Específicamente esta probabilidad es \[\begin{eqnarray} \beta & = & P(\text{Error tipo II}) \\ & = & P(\text{No rechazar } H_0 \mid H_0 \text{ es falsa}) \\ & = & P(|\overline{X} - \theta| < c \mid \theta \neq 1/2). \end{eqnarray}\]
La imposibilidad de calcular esta probabilidad radica en que el valor de \(\theta\) no está determinado y, en consecuencia, la distribución de \(\overline{X}\) no está plenamente especificada. Una manera parcial de calcular la probabilidad del error tipo II es considerarla como una función del parámetro, esto es, se fija un valor \(\theta_1\) distinto de 1/2 y se calcula la siguiente cantidad
\[\begin{eqnarray} \beta(\theta_1) & = & P(|\overline{X} - \theta_1| < c \mid \theta = \theta_1) \\ & = & P\left( -c < \overline{X} - \theta_1 < c \mid \theta = \theta_1 \right) \\ & = & P\left( \frac{-c}{\sqrt{\theta_1(1-\theta_1)/n}} < \frac{\overline{X} - \theta_1}{\sqrt{\theta_1(1-\theta_1)/n}} < \frac{c}{\sqrt{\theta_1(1-\theta_1)/n}} \mid \theta = \theta_1 \right) \\ & \approx & \Phi\left( \frac{c}{\sqrt{\theta_1(1-\theta_1)/n}} \right) - \Phi\left( \frac{-c}{\sqrt{\theta_1(1-\theta_1)/n}} \right) \end{eqnarray}\]
La gráfica de esta función se muestra en la siguiente figura, donde se observa que conforme el valor de \(\theta_1\) se aleja de 1/2, la probabilidad de equivocarse del tipo II disminuye.
Código
alpha <- 0.05
c <- 1/(2*sqrt(n)) * qnorm(1 - alpha / 2)
theta_1_vals <- seq(0.001, 0.999, by = 0.005)
beta_vals <- pnorm(c / sqrt(theta_1_vals * (1 - theta_1_vals) / n)) - pnorm(-c / sqrt(theta_1_vals * (1 - theta_1_vals) / n))
ggplot(data.frame(theta_1 = theta_1_vals, beta = beta_vals), aes(x = theta_1, y = beta)) +
geom_line(color = "purple4", linewidth = 1.3) +
annotate("point", x = 0.5, y = pnorm( c / sqrt(0.5 * (1 - 0.5) / n)) - pnorm(-c / sqrt(0.5 * (1 - 0.5) / n)), shape = 21, color = "firebrick", fill = "white", size = 3) +
labs(x = expression(theta[1]),
y = expression(beta(theta[1]))) +
theme_minimal()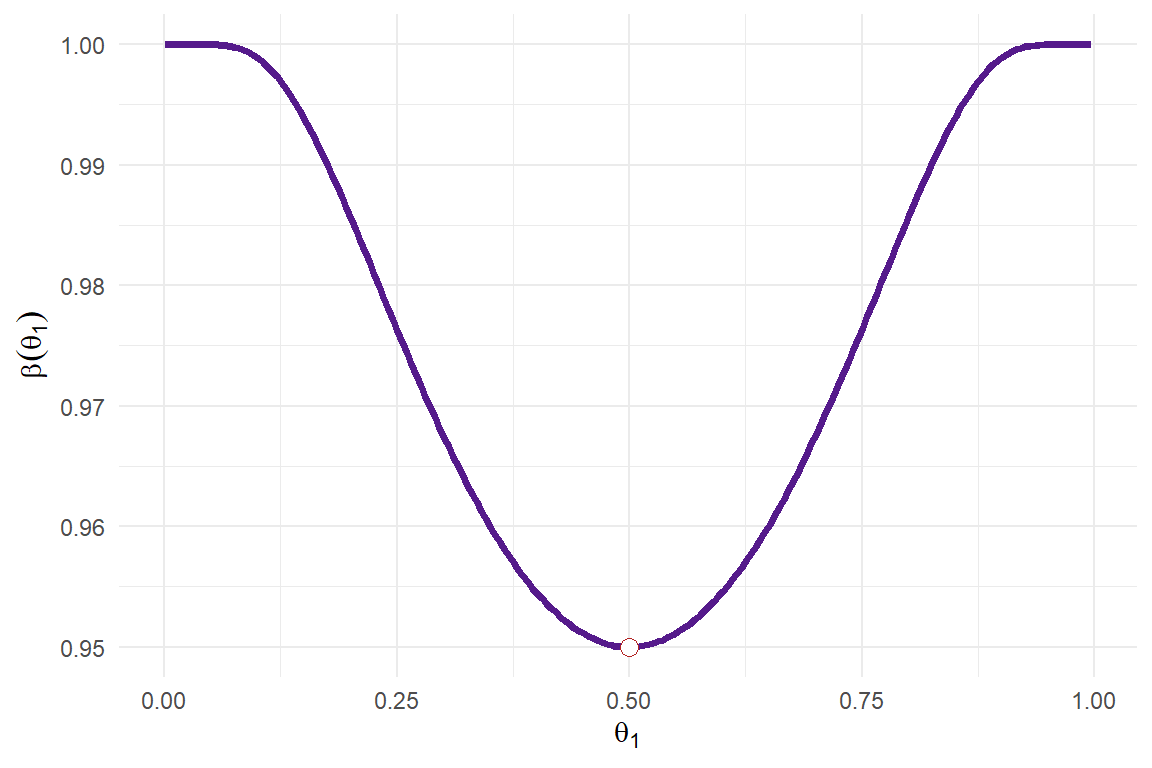
Observemos que se ha utilizado el teorema central del límite para obtener una aproximación de esta probabilidad. De esta forma el error tipo II queda expresado como una función del valor de \(\theta_1\) distinto de 1/2. La función potencia de esta prueba se muestra en la siguiente gráfica.
Código
theta_vals <- seq(0.001, 0.999, by = 0.005)
pi_vals <- 1 - (pnorm(c / sqrt(theta_vals * (1 - theta_vals) / n)) - pnorm(-c / sqrt(theta_vals * (1 - theta_vals) / n)))
ggplot(data.frame(theta = theta_vals, pi = pi_vals), aes(x = theta, y = pi)) +
geom_line(color = "seagreen4", linewidth = 1.3) +
annotate("segment", x = 0.5, xend = 0.5, y = 0, yend = 1 - (pnorm(c / sqrt(0.5 * (1 - 0.5) / n)) - pnorm(-c / sqrt(0.5 * (1 - 0.5) / n))), color = "red", linetype = "dashed") +
annotate("segment", x = 0, xend = 0.5, y = 1 - (pnorm(c / sqrt(0.5 * (1 - 0.5) / n)) - pnorm(-c / sqrt(0.5 * (1 - 0.5) / n))), yend = 1 - (pnorm(c / sqrt(0.5 * (1 - 0.5) / n)) - pnorm(-c / sqrt(0.5 * (1 - 0.5) / n))), color = "red", linetype = "dashed") +
labs(x = expression(theta),
y = expression(pi(theta))) +
theme_minimal()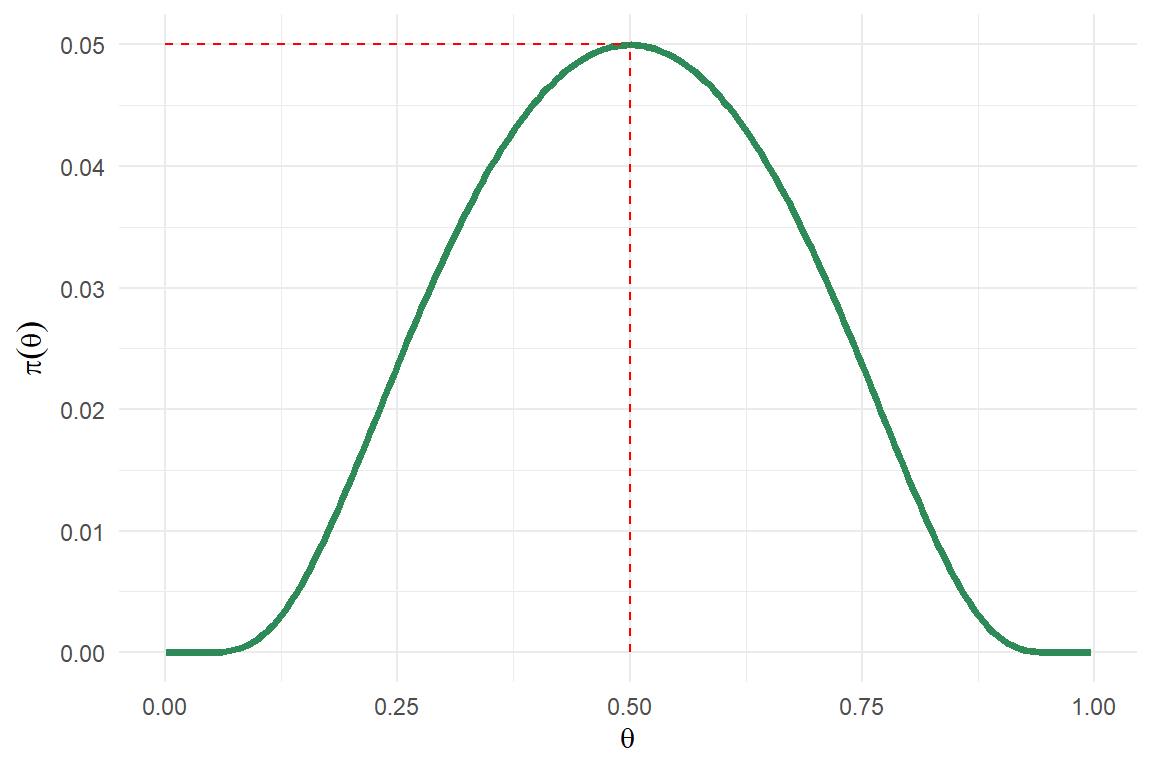
Más adelante consideraremos el caso sencillo cuando tenemos dos hipótesis simples para un parámetro \(H_0:\, \theta=\theta_0\) contra \(H_1:\, \theta=\theta_1\), y el problema que estudiaremos será el de encontrar una región de rechazo que sea de tamaño predeterminado \(\alpha\) y cuya probabilidad de error tipo II sea mínima.
6.5 Algunas pruebas de hipótesis sobre la distribució normal
En esta sección se presentan algunas pruebas de hipótesis comunes sobre el valor de los parámetros de una distribución normal. Entre otras cantidades, los resultados quedarán expresados en términos de algún valor \(z_\alpha\), el cual se define como aquel número real tal que \(P(Z>z_\alpha)=\alpha\), en donde \(\alpha\in(0,1)\) y \(Z\) denota una variable aleatoria con distribución \(N(0,1)\). En otras palabras, \(z_\alpha\) denota aquel número que acumula al aderecha una probabilidad igual a \(\alpha\) en la distribución normal estándar. Recordemos además que a la función de distribución normal estándar la denotamos por \(\Phi(x)\). Esto es, \(\Phi(x)=P(Z\leq x)\), definida para cualquier número real \(x\). Así, por ejemplo tenemos que \(\Phi(z_\alpha)=1-\alpha\).
6.5.1 Prueba para la media con varianza conocida
Sea \(X_1, X_2, \dots, X_n\) una muestra aleatoria de tamaño \(n\) proveniente de una población con distribución normal \(N(\theta, \sigma^2)\), en donde la media \(\theta\) es desconocida y consideramos que \(\sigma^2\) es conocida. Entonces la media muestral \(\overline{X}\) tiene distribución \(N(\theta, \sigma^2/n)\). Por lotanto, \[Z = \frac{\overline{X} - \theta}{\sigma/\sqrt{n}} \sim N(0,1).\]
Las pruebas que consideraremos hacen referencia a un valor particular \(\theta_0\) del parámetro desconocido \(\theta\).
6.5.1.1 Prueba bilateral o de dos colas.
Deseamos contrastar las hipótesis \[H_0: \theta = \theta_0 \quad vs \quad H_1: \theta \neq \theta_0.\] El problema es encontrar una regla para decidir cuándo rechazar \(H_0\) en favor de \(H_1\), con base en los datos de la muestra aleatoria. Cuando \(H_0\) es cierta, esto es, cuando \(\theta=\theta_0\), tenemos que \[\overline{X} \sim N(\theta_0, \sigma^2/n).\] Por lo tanto, la estadística de prueba es la variable aleatoria \[Z_0 = \frac{\overline{X} - \theta_0}{\sigma/\sqrt{n}} \sim N(0,1).\] La estadística \(Z_0\) es una medida de la distancia entre \(\overline{X}\) (un estimador de \(\theta\)), y su valor esperado \(\theta_0\) cuando \(H_0\) es cierta. Es entonces razonable rechazar \(H_0\) cuando la variable \(Z_0\) sea grande. Esta es la razón por la que tomamos como criterio de la decisión rechazar \(H_0\) cuando \(|Z_0|\geq c\), para cierta constante \(c\). ¿Cómo encontramos el número \(c\)? Con R, considerando la distribución normal podemos encontrar un valor \(z_{\alpha/2}\) tal que \(P(|Z|\geq z_{\alpha/2})=\alpha\), para un valor de \(\alpha\) preestablecido (ver la siguiente figura). Este valor \(z_{\alpha/2}\), también llamado \(z\) crítico y denotado \(z_{crit}\), es precisamente la constante \(c\) buscada pues con ello se logra que la región de rechazo sea de tamaño \(\alpha\).
Código
# Crear datos para la curva normal
x <- seq(-4, 4, length.out = 1000)
y <- dnorm(x)
# Valor crítico para alpha = 0.05
z_alpha <- qnorm(0.975)
# Crear el gráfico
ggplot(data.frame(x = x, y = y), aes(x, y)) +
geom_line(linewidth = 1) +
# Área central (1-alpha)
geom_area(data = data.frame(x = x[x >= -z_alpha & x <= z_alpha],
y = y[x >= -z_alpha & x <= z_alpha]),
aes(x, y), fill = "darkgoldenrod", alpha = 0.7) +
# Áreas en las colas (alpha/2 cada una)
geom_area(data = data.frame(x = x[x <= -z_alpha],
y = y[x <= -z_alpha]),
aes(x, y), fill = "gold1", alpha = 0.7) +
geom_area(data = data.frame(x = x[x >= z_alpha],
y = y[x >= z_alpha]),
aes(x, y), fill = "gold1", alpha = 0.7) +
# Líneas verticales
geom_vline(xintercept = c(-z_alpha, z_alpha), linetype = "dashed") +
# Anotaciones
annotate("label", x = -z_alpha, y = -0.02, label = "-z[alpha/2]", parse = TRUE, size = 4) +
annotate("label", x = z_alpha, y = -0.02, label = "z[alpha/2]", parse = TRUE,size = 4) +
annotate("text", x = -3, y = 0.05, label = "alpha/2", parse = TRUE, size = 5) +
annotate("text", x = 3, y = 0.05, label = "alpha/2", parse =TRUE, size = 5) +
annotate("text", x = 0, y = 0.25, label = "1-alpha", parse=TRUE, size = 6) +
# Texto "Rechazar H₀"
annotate("label", x = 0, y = 0.15, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
# Flechas apuntando a la región
annotate("curve", x = 1.2, y = 0.15, xend = 3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = -0.3, color = "black") +
annotate("curve", x = -1.2, y = 0.15, xend = -3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0.3, color = "black") +
labs(x = "x", y = expression(phi(x))) +
theme_minimal() +
theme(axis.title = element_text(size = 13))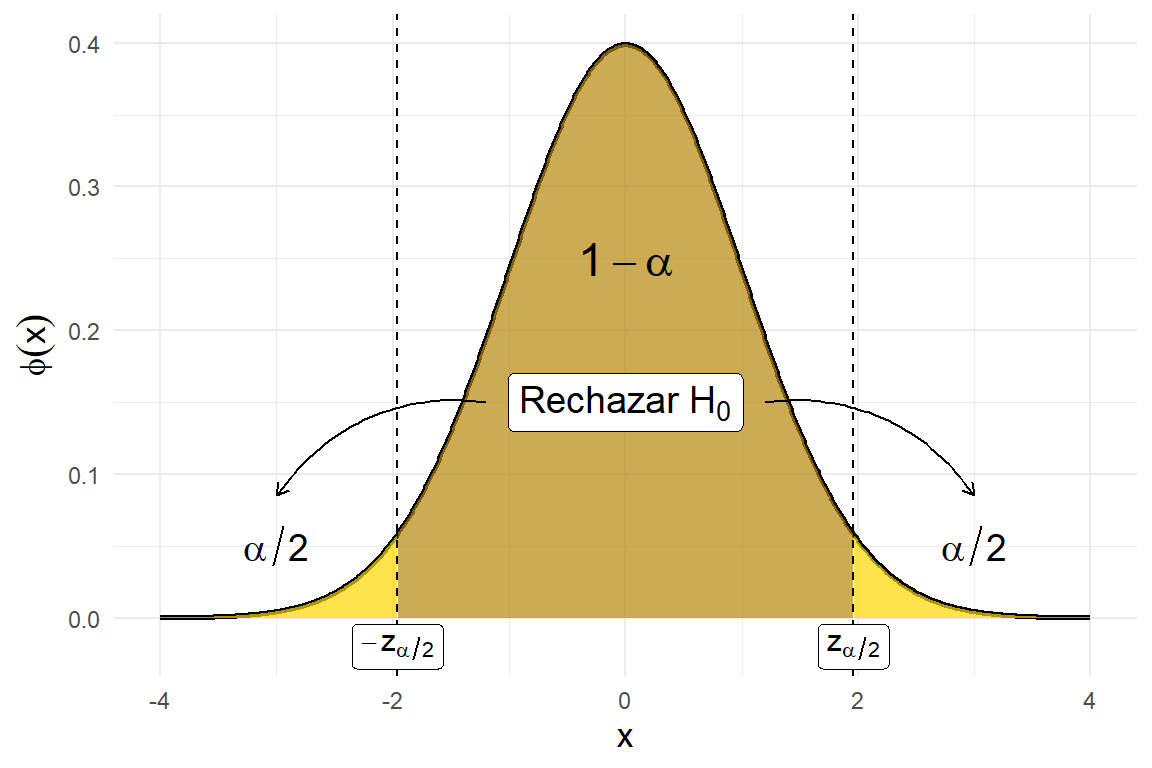
A la variable aleatoria \(Z_0\) se le llama estadística de prueba, y la prueba se denomina prueba bilateral pues la región de rechazo consta de las dos colas de la distribución normal estándar que se muestran en la figura anterior. Llevar a cabo esta prueba de hipótesis consiste simplemente en usar los datos de la muestra para encontrar el valor de \(Z_0\). Si resulta que \(|Z_0|\geq z_{\alpha/2}\), entonces se rechaza \(H_0\), en caso contrario no se rechaza \(H_0\). Es decir, la región de rechazo de tamaño \(\alpha\) es \[\mathscr{C} = \{ (x_1, x_2, \dots, x_n) \mid \left|\frac{\overline{x}-\theta_0}{\sigma/\sqrt{n}}\right| \geq z_{\alpha/2} \}.\] Puede comprobarse que la probabilidad de no rechazar \(H_0\) cuando \(\theta=\theta_1\) (un valor distinto de \(\theta_0\)) es
\[\begin{eqnarray} \beta(\theta_1) & = & P(\text{No rechazar } H_0 \mid \theta = \theta_1) \\ & = & P(|Z_0| < z_{\alpha/2} \mid \theta = \theta_1) \\ & = & P\left( -z_{\alpha/2} < \frac{\overline{X} - \theta_0}{\sigma/\sqrt{n}} < z_{\alpha/2} \mid \theta = \theta_1 \right) \\ & = & \Phi\left( z_{\alpha/2} + \frac{\theta_0-\theta_1}{\sigma/\sqrt{n}} \right) - \Phi\left(-z_{\alpha/2} + \frac{\theta_0-\theta_1}{\sigma/\sqrt{n}} \right) \end{eqnarray}\]
6.5.1.2 Prueba de cola inferior
Ahora consideremos la prueba de hipótesis \[H_0: \theta = \theta_0 \quad vs \quad H_1: \theta < \theta_0.\] A esta prueba se le llama prueba de cola inferior, pues la región de rechazo se encuentra en la cola izquierda de la distribución normal estándar (como se muestra en la siguiente figura). El procedimiento de construcción de la región de rechazo es análogo a la prueba bilateral. Ahora se rechaza la hipótesis \(H_0\) sólo cuando \(\overline{X}\) toma un valor muy a la izquierda de \(\theta_0\). Así, tenemos nuevamente que cuando \(H_0\) es cierta, \[Z_0 = \frac{\overline{X} - \theta_0}{\sigma/\sqrt{n}} \sim N(0,1),\] y se rechaza la hipótesis nula \(H_0\) cuando \(Z_0 \leq c\), para alguna constante negativa \(c\). Como se desea que esta región de rechazo tenga tamaño \(\alpha\), la constante \(c\) debe ser igual \(-z_\alpha\), como se ilustra a continuación.
Código
# Crear datos para la curva normal
x <- seq(-4, 4, length.out = 1500)
y <- dnorm(x)
# Valor crítico para alpha = 0.05
z_alpha <- qnorm(0.95)
# Crear el gráfico
ggplot(data.frame(x = x, y = y), aes(x, y)) +
geom_line(linewidth = 1) +
# Área central (1-alpha)
# Áreas en las colas (alpha/2 cada una)
geom_area(data = data.frame(x = x[x <= -z_alpha],
y = y[x <= -z_alpha]),
aes(x, y), fill = "olivedrab3") +
# Líneas verticales
geom_vline(xintercept = c(-z_alpha), linetype = "dashed") +
# Anotaciones
annotate("label", x = -z_alpha, y = -0.02, label = "-z[alpha]", parse = TRUE, size = 4) +
annotate("text", x = -3, y = 0.05, label = "alpha", parse = TRUE, size = 5) +
# Texto "Rechazar H₀"
annotate("text", x = -3, y = 0.2, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
annotate("curve", x = -3, y = 0.175, xend = -3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0, color = "black") +
labs(x = "x", y = expression(phi(x))) +
theme_minimal() +
theme(axis.title = element_text(size = 13))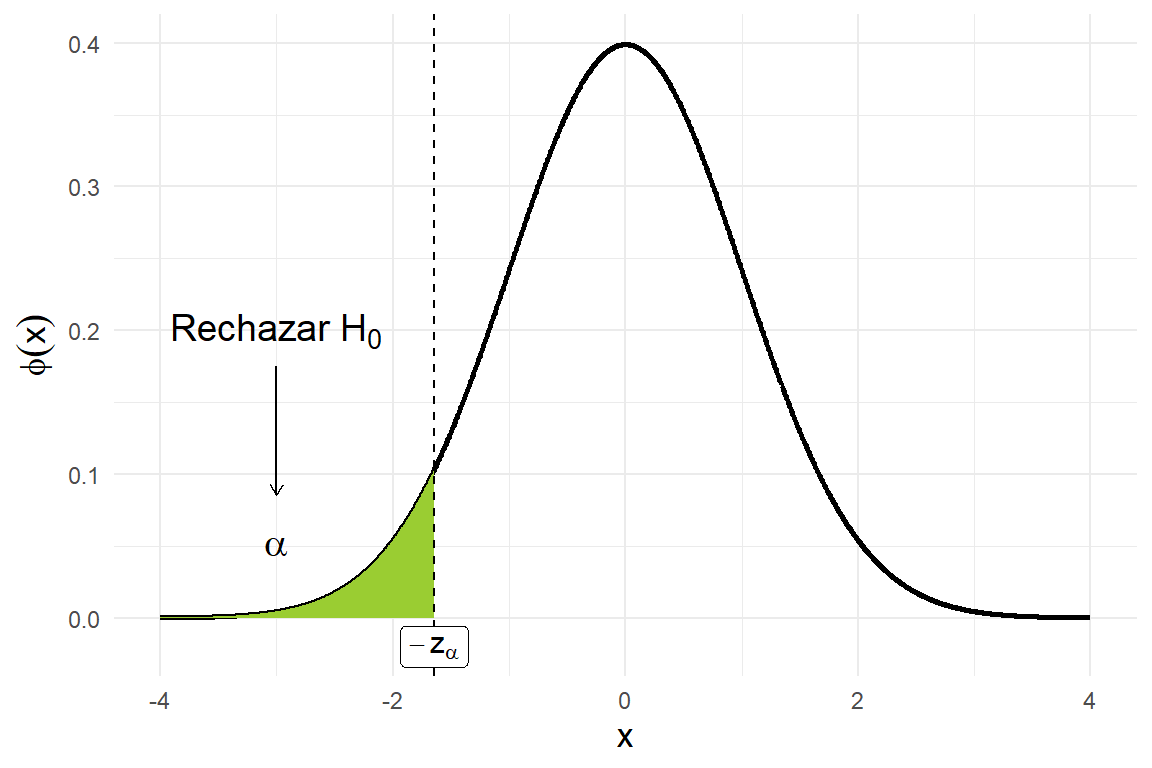
Así, la región de rechazo de tamaño \(\alpha\) es \[\mathscr{C} = \{ (x_1, x_2, \dots, x_n) \mid \frac{\overline{x} - \theta_0}{\sigma/\sqrt{n}} \leq -z_\alpha \}.\]
Puede comprobarse que la probabilidad de no rechazar \(H_0\) cuando \(\theta=\theta_1 < \theta_0\) es
\[\begin{eqnarray} \beta(\theta_1) & = & P(\text{No rechazar } H_0 \mid \theta = \theta_1) \\ & = & P\left( \frac{\overline{X} - \theta_0}{\sigma/\sqrt{n}} > -z_\alpha \mid \theta = \theta_1 \right) \\ & = & P\left( \frac{z_\alpha \sigma/\sqrt{n} + \theta_0 - \theta_1}{\sigma/\sqrt{n}} < \frac{\overline{X} - \theta_1}{\sigma/\sqrt{n}} \mid \theta = \theta_1 \right) \\ & = & 1 - \Phi\left( -z_{\alpha} + \frac{\theta_0 - \theta_1}{\sigma/\sqrt{n}} \right). \end{eqnarray}\]
6.5.1.3 Prueba de cola superior
Consideremos ahora la prueba \[H_0 : \theta = \theta_0 \quad vs \quad H_1 : \theta > \theta_0,\]
llamada prueba de cola superior. Se rechaza la hipótesis \(H_0\) cuando \(\overline{X}\) toma un valor muy a la derecha de \(\theta_0\). Tenemos nuevamente que, cuando \(H_0\) es cierta,
\[Z_0 = \frac{\overline{X} - \theta_0}{\sigma/\sqrt{n}} \sim N(0, 1),\]
y se rechaza la hipótesis \(H_0\) si \(Z_0 \geq c\), para alguna constante positiva \(c\). Como se desea que esta región de rechazo tenga tamaño \(\alpha\), la constante \(c\) debe ser igual al cuantil \(z_\alpha\). Es decir, la región de rechazo de tamaño \(\alpha\) es
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \frac{\overline{x} - \theta_0}{\sigma/\sqrt{n}} \geq z_\alpha\}.\]
Esto se ilustra en la siguiente gráfica.
Código
# Crear datos para la curva normal
x <- seq(-4, 4, length.out = 1500)
y <- dnorm(x)
# Valor crítico para alpha = 0.05
z_alpha <- qnorm(0.95)
# Crear el gráfico
ggplot(data.frame(x = x, y = y), aes(x, y)) +
geom_line(linewidth = 1) +
# Área central (1-alpha)
geom_area(data = data.frame(x = x[x >= z_alpha],
y = y[x >= z_alpha]),
aes(x, y), fill = "dodgerblue2", alpha = 0.7) +
# Líneas verticales
geom_vline(xintercept = c(z_alpha), linetype = "dashed") +
# Anotaciones
annotate("label", x = z_alpha, y = -0.02, label = "z[alpha]", parse = TRUE,size = 4) +
annotate("text", x = 3, y = 0.05, label = "alpha", parse =TRUE, size = 5) +
annotate("text", x = 3, y = 0.2, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
# Flechas apuntando a la región
annotate("curve", x = 3, y = 0.175, xend = 3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0, color = "black") +
labs(x = "x", y = expression(phi(x))) +
theme_minimal() +
theme(axis.title = element_text(size = 13))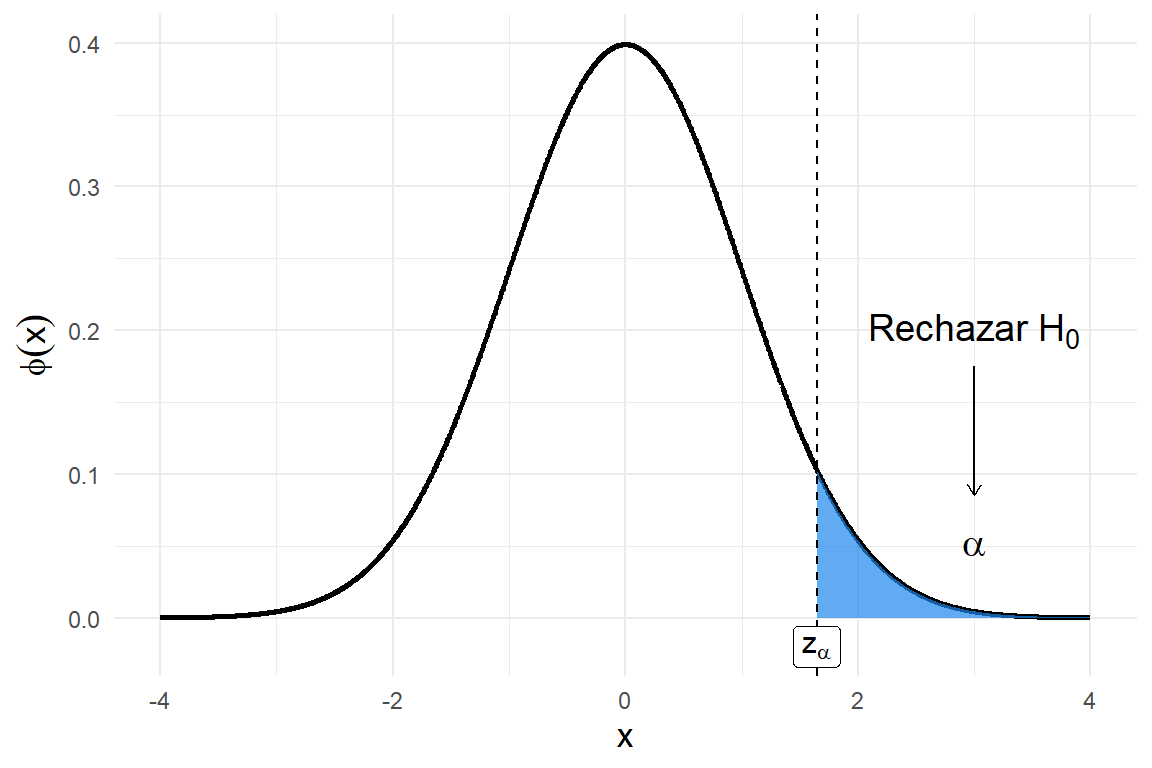
Nuevamente, es inmediato comprobar que la probabilidad de no rechazar la hipótesis nula cuando \(\theta = \theta_1\) (con \(\theta_1 > \theta_0\)) es
\[\beta(\theta_1) = P(Z < z_\alpha | \theta = \theta_1) = \Phi\left(z_\alpha + \frac{\theta_0 - \theta_1}{\sigma/\sqrt{n}}\right).\]
6.5.2 Pruebas para la media con varianza desconocida
Consideremos nuevamente una muestra aleatoria \(X_1,\ldots,X_n\) de la distribución normal con media desconocida \(\theta\), pero ahora con varianza desconocida \(\sigma^2\). Nos interesa encontrar una regla de decisión para llevar a cabo ciertas pruebas de hipótesis sobre el valor desconocido del parámetro \(\theta\). El procedimiento es muy similar al caso cuando \(\sigma^2\) es conocida y el resultado teórico que es de utilidad aquí es que
\[\frac{\overline{X} - \theta}{S/\sqrt{n}} \sim t(n - 1),\]
en donde \(S\) es la varianza muestral. Como en el caso anterior, las pruebas que consideraremos hacen referencia a un valor particular \(\theta_0\) del parámetro desconocido \(\theta\).
6.5.2.1 Prueba bilateral
Consideremos la prueba \[H_0 : \theta = \theta_0 \quad vs \quad H_1 : \theta \neq \theta_0.\]
Es razonable rechazar \(H_0\) cuando la diferencia entre la media muestral \(\overline{X}\) y el valor \(\theta_0\) es grande, es decir, cuando \(|\overline{X} - \theta_0| \geq c\), para alguna constante \(c\). Así, es de utilidad saber que
\[T_0 = \frac{\overline{X} - \theta_0}{S/\sqrt{n}} \sim t(n - 1),\]
pues esta variable aleatoria es una medida de la distancia entre \(\overline{X}\) y \(\theta_0\). Además, si \(t_{\alpha/2,n-1}\) denota el número real tal que el área bajo la función de densidad de la distribución \(t(n - 1)\) a la derecha de ese valor es \(\alpha/2\), entonces una región de rechazo de tamaño \(\alpha\) para esta prueba es
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \left|\frac{\overline{x} - \theta_0}{s/\sqrt{n}}\right| \geq t_{\alpha/2,n-1}\}.\]
Código
# Crear datos para la curva
x <- seq(-4, 4, length.out = 1500)
y <- dt(x, df = 10)
# Valor crítico para alpha = 0.05
t_alpha <- qt(0.975, df=10)
# Crear el gráfico
ggplot(data.frame(x = x, y = y), aes(x, y)) +
geom_line(linewidth = 1) +
# Área central (1-alpha)
geom_area(data = data.frame(x = x[x >= -t_alpha & x <= t_alpha],
y = y[x >= -t_alpha & x <= t_alpha]),
aes(x, y), fill = "coral4", alpha = 0.7) +
# Áreas en las colas (alpha/2 cada una)
geom_area(data = data.frame(x = x[x <= -t_alpha],
y = y[x <= -t_alpha]),
aes(x, y), fill = "coral1", alpha = 0.7) +
geom_area(data = data.frame(x = x[x >= t_alpha],
y = y[x >= t_alpha]),
aes(x, y), fill = "coral1", alpha = 0.7) +
# Líneas verticales
geom_vline(xintercept = c(-t_alpha, t_alpha), linetype = "dashed") +
# Anotaciones
annotate("label", x = -t_alpha, y = -0.02, label = "-t[alpha/2~n-1]", parse = TRUE, size = 4) +
annotate("label", x = t_alpha, y = -0.02, label = "t[alpha/2~n-1]", parse = TRUE,size = 4) +
annotate("text", x = -3, y = 0.05, label = "alpha/2", parse = TRUE, size = 5) +
annotate("text", x = 3, y = 0.05, label = "alpha/2", parse =TRUE, size = 5) +
annotate("text", x = 0, y = 0.25, label = "1-alpha", parse=TRUE, size = 6) +
# Texto "Rechazar H₀"
annotate("label", x = 0, y = 0.15, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
# Flechas apuntando a la región
annotate("curve", x = 1.2, y = 0.15, xend = 3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = -0.3, color = "black") +
annotate("curve", x = -1.2, y = 0.15, xend = -3, yend = 0.085,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0.3, color = "black") +
labs(x = "x", y = expression(f(x))) +
theme_minimal() +
theme(axis.title = element_text(size = 13))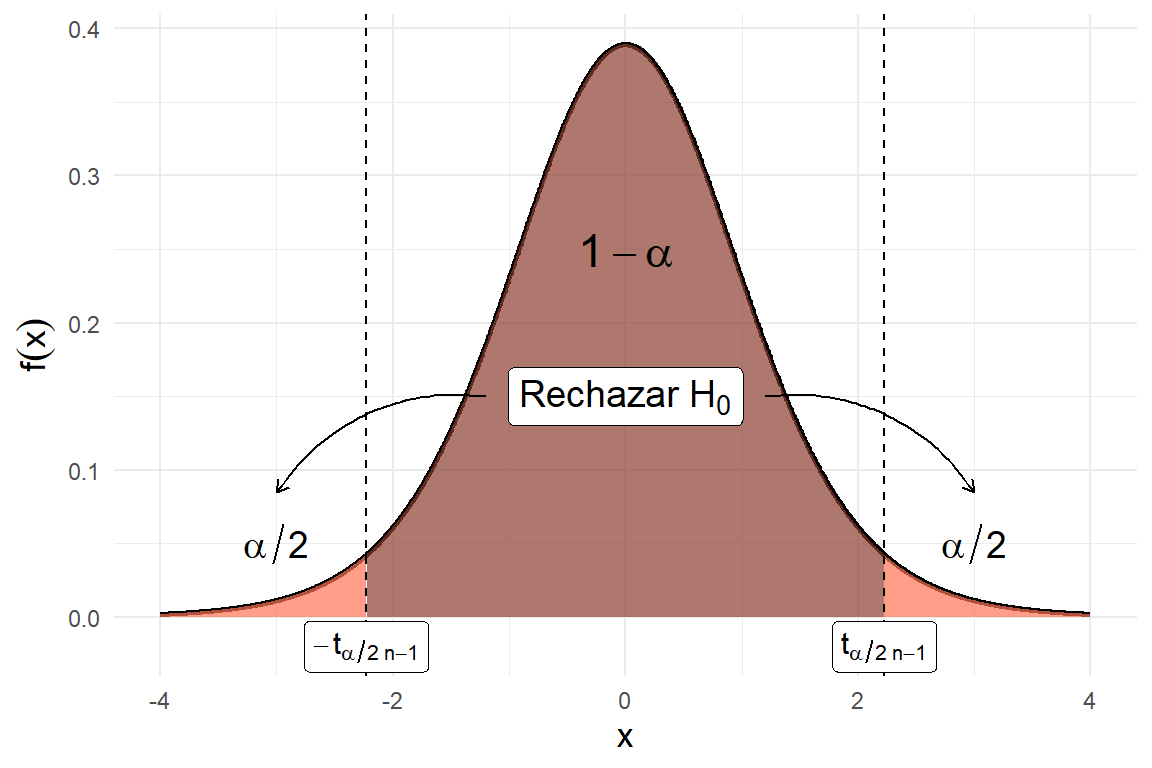
Respecto del error tipo II para esta región de rechazo, puede comprobarse que la probabilidad de no rechazar \(H_0\) cuando \(\theta = \theta_1\) (con \(\theta_1\) distinto de \(\theta_0\)) es
\[\begin{eqnarray} \beta(\theta_1) & = & P(|T_0| < t_{\alpha/2,n-1} | \theta = \theta_1) \\ & \approx & F\left(t_{\alpha/2,n-1} + \frac{\theta_0 - \theta_1}{s/\sqrt{n}}\right) - F\left(-t_{\alpha/2,n-1} + \frac{\theta_0 - \theta_1}{s/\sqrt{n}}\right), \end{eqnarray}\]
en donde \(F\) es la función de distribución \(t\) con \(n - 1\) grados de libertad. Observe que la última expresión es una aproximación pues se ha substituido la desviación estándar muestral \(S\) por su valor observado \(s\).
6.5.2.2 Prueba de cola inferior
La prueba \(H_0 : \theta = \theta_0\) vs \(H_1 : \theta < \theta_0\) se llama nuevamente prueba de cola inferior y una región de rechazo de tamaño prefijado \(\alpha\) está dada por
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \frac{\overline{x} - \theta_0}{s/\sqrt{n}} \leq t_{\alpha,n-1}\},\]
en donde \(t_{\alpha,n-1}\) es el cuantil de la distribución \(t(n - 1)\) al nivel \(\alpha\). Respecto del error tipo II para esta región de rechazo, la probabilidad de no rechazar \(H_0\) cuando \(\theta = \theta_1\), en donde \(\theta_1\) es un valor menor a \(\theta_0\), se puede comprobar que
\[\beta(\theta_1) = P\left(\frac{\overline{X} - \theta_0}{S/\sqrt{n}} > t_{\alpha,n-1} | \theta = \theta_1\right) \approx 1 - F\left(t_{\alpha,n-1} + \frac{\theta_0 - \theta_1}{s/\sqrt{n}}\right),\]
en donde \(F\) denota la función de distribución \(t(n - 1)\). La última expresión es únicamente una aproximación a la probabilidad buscada pues se ha reemplazado la desviación estándar muestral \(S\) por su valor observado \(s\).
6.5.2.3 Prueba de cola superior
Finalmente para la prueba de cola superior \(H_0 : \theta = \theta_0\) vs \(H_1 : \theta > \theta_0\) se conocen los siguientes resultados. Una región de rechazo de tamaño prefijado \(\alpha\) está dada por
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \frac{\overline{x} - \theta_0}{s/\sqrt{n}} \geq t_{\alpha,n-1}\},\]
en donde \(t_{\alpha,n-1}\) es el cuantil de la distribución \(t(n - 1)\) al nivel \(\alpha\). Respecto del error tipo II para esta región de rechazo, la probabilidad de no rechazar \(H_0\) cuando \(\theta = \theta_1\), en donde \(\theta_1\) es un valor mayor a \(\theta_0\), se puede comprobar que
\[\beta(\theta_1) = P\left(\frac{\overline{X} - \theta_0}{S/\sqrt{n}} < t_{\alpha,n-1} | \theta = \theta_1\right) \approx F\left(t_{\alpha,n-1} + \frac{\theta_0 - \theta_1}{s/\sqrt{n}}\right),\]
en donde \(F\) denota la función de distribución \(t(n - 1)\). Nuevamente, se ha escrito sólo una aproximación a la verdadera probabilidad del error tipo II pues se ha substituido la desviación estándar muestral \(S\) por su valor observado \(s\).
6.5.3 Pruebas para la diferencia entre dos medias con varianzas conocidas
Sean \(X_1,\ldots,X_n\) y \(Y_1,\ldots,Y_m\) dos muestras aleatorias independientes de dos poblaciones, con distribución \(N(\theta_X, \sigma_X^2)\) y \(N(\theta_Y, \sigma_Y^2)\), respectivamente. Supondremos que las medias \(\theta_X\) y \(\theta_Y\) son desconocidas y que las varianzas \(\sigma_X^2\) y \(\sigma_Y^2\) son conocidas y pueden ser diferentes. Observe que el tamaño de las muestras puede ser distinto. En esta sección encontraremos un criterio para probar la hipótesis simple
\[H_0 : \theta_X - \theta_Y = \delta,\]
contra alguna hipótesis alternativa, en donde \(\delta\) es una constante. Mediante estas pruebas se puede decidir si las medias de las dos poblaciones normales difieren en la constante \(\delta\) o en una cantidad diferente. El procedimiento es muy similar a las pruebas presentadas antes sobre la media desconocida de una distribución normal con varianza conocida.
Sean \(\overline{X}\) y \(\overline{Y}\) las correspondientes medias muestrales. Sabemos que \(\overline{X}\) tiene distribución \(N(\theta_X, \sigma_X^2/n)\) y \(\overline{Y}\) tiene distribución \(N(\theta_Y, \sigma_Y^2/m)\). Entonces
\[\overline{X} - \overline{Y} \sim N\left(\theta_X - \theta_Y, \frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}\right).\]
Este es el resultado que nos llevará a encontrar una regla para decidir cuándo rechazar \(H_0\) en favor de alguna hipótesis alternativa, con base en los datos de las muestras aleatorias.
6.5.3.1 Prueba bilateral
Consideraremos primero el caso cuando la hipótesis alternativa es
\[H_1 : \theta_X - \theta_Y \neq \delta.\]
Cuando \(H_0\) es cierta, esto es, cuando \(\theta_X - \theta_Y = \delta\), tenemos que \(\overline{X} - \overline{Y}\) tiene distribución \(N(\delta, \sigma_X^2/n + \sigma_Y^2/m)\), y por lo tanto,
\[Z_0 := \frac{\overline{X} - \overline{Y} - \delta}{\sqrt{\frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}}} \sim N(0, 1).\]
La estadística \(Z_0\) es nuevamente una medida de la distancia entre la diferencia \(\overline{X} - \overline{Y}\) y \(\delta\). Es entonces razonable rechazar \(H_0\) cuando la variable \(Z_0\) sea grande en valor absoluto. Es por ello que tomamos como criterio de decisión rechazar \(H_0\) cuando \(|Z_0| \geq c\), para cierta constante \(c\). En una tabla de la distribución normal estándar podemos encontrar un valor \(z_{\alpha/2}\) tal que \(P(|Z| \geq z_{\alpha/2}) = \alpha\), en donde \(\alpha\) es valor preestablecido para la probabilidad del error tipo I. Este valor \(z_{\alpha/2}\) es la constante \(c\) buscada y con ello se logra que la región de rechazo sea de tamaño \(\alpha\).
\[\mathscr{C} = \{(x_1,\ldots,x_n) : |Z_0| \geq z_{\alpha/2}\}.\]
Respecto del error tipo II, para un valor \(\delta_1\) distinto de \(\delta\), es inmediato comprobar que la probabilidad de no rechazar la hipótesis nula dado que \(\theta_X - \theta_Y = \delta_1\) es
\[\beta(\delta_1) = P(|Z_0| < z_{\alpha/2} | \theta_X - \theta_Y = \delta_1) = \Phi\left(z_{\alpha/2} + \frac{\delta - \delta_1}{\sqrt{\frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}}}\right) - \Phi\left(-z_{\alpha/2} + \frac{\delta - \delta_1}{\sqrt{\frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}}}\right).\]
6.5.3.2 Prueba de cola inferior
Consideremos ahora como hipótesis alternativa
\[H_1 : \theta_X - \theta_Y < \delta,\]
Siguiendo el mismo razonamiento que antes, ahora rechazamos \(H_0\) cuando la estadística \(Z_0\) toma un valor menor a una cierta constante. El valor de esta constante que hace que la región de rechazo sea de tamaño \(\alpha\) es \(-z_\alpha\). Así, la región de rechazo propuesta es
\[\mathscr{C} = \{(x_1,\ldots,x_n) : Z_0 \leq -z_\alpha\}.\]
Respecto del error tipo II, para un valor \(\delta_1\) menor a \(\delta\), la probabilidad de no rechazar \(H_0\) dado que \(\theta_X - \theta_Y = \delta_1\) es
\[\beta(\delta_1) = P(Z_0 > -z_\alpha | \theta_X - \theta_Y = \delta_1) = 1 - \Phi\left(-z_\alpha + \frac{\delta - \delta_1}{\sqrt{\frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}}}\right).\]
6.5.3.3 Prueba de cola superior
Finalmente consideremos como hipótesis alternativa
\[H_1 : \theta_X - \theta_Y > \delta.\]
Ahora rechazamos \(H_0\) cuando la estadística \(Z_0\) toma un valor mayor a una cierta constante. El valor de esta constante que hace que la región de rechazo sea de tamaño \(\alpha\) es \(z_\alpha\). Así, la región de rechazo propuesta es
\[\mathscr{C} = \{(x_1,\ldots,x_n) : Z_0 \geq z_\alpha\}.\]
Respecto del error tipo II, para un valor \(\delta_1\) mayor a \(\delta\), la probabilidad de no rechazar \(H_0\) dado que \(\theta_X - \theta_Y = \delta_1\) es
\[\beta(\delta_1) = P(Z_0 < z_\alpha | \theta_X - \theta_Y = \delta_1) = \Phi\left(z_\alpha + \frac{\delta - \delta_1}{\sqrt{\frac{\sigma_X^2}{n} + \frac{\sigma_Y^2}{m}}}\right).\]
6.5.4 Pruebas para la varianza
Consideremos nuevamente una muestra aleatoria \(X_1,\ldots,X_n\) proveniente de \(n\) observaciones de una variable aleatoria con distribución \(N(\mu, \sigma^2)\), con ambos parámetros desconocidos. Nos interesa ahora encontrar un mecanismo para probar la hipótesis nula \(H_0 : \sigma^2 = \sigma_0^2\) contra alguna hipótesis alternativa. Un manera de encontrar una regla de decisión para estas pruebas hace uso del resultado teórico que establece que
\[\chi_0^2 := \frac{(n - 1)S^2}{\sigma_0^2} \sim \chi^2(n - 1),\]
cuando la varianza desconocida \(\sigma^2\) es, efectivamente, \(\sigma_0^2\). Como antes, el término \(S^2\) denota la varianza muestral. Por otro lado, recordemos que la esperanza de una variable aleatoria con distribución \(\chi^2(n-1)\) es el parámetro \(n-1\), y por lo tanto, \(E(\chi_0^2) = n-1\). De esta manera se propone rechazar la hipótesis \(H_0\) cuando la variable aleatoria \(\chi_0^2\) tome un valor lejano de su valor central \(n - 1\).
6.5.4.1 Prueba bilateral
Para la prueba \(H_0 : \sigma^2 = \sigma_0^2\) vs \(H_1 : \sigma^2 \neq \sigma_0^2\), se propone rechazar \(H_0\) cuando la variable \(\chi_0^2\) está alejada de su valor central tomando un valor en una de las dos colas de su distribución. Estas dos colas se establecen en la siguiente región de rechazo, la cual tiene tamaño \(\alpha\):
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \chi_0^2 < \chi_{1-\alpha/2}^2 \text{ ó } \chi_0^2 > \chi_{\alpha/2}^2\},\]
en donde \(\chi_{\alpha/2}^2\) es el número real tal que la distribución \(\chi^2(n - 1)\) acumula a la derecha probabilidad \(\alpha/2\). Análogamente, la probabilidad a la derecha del número \(\chi_{1-\alpha/2}^2\) es \(1 - \alpha/2\). Véase la siguiente figura para una representación gráfica de estas cantidades, así como de la región de rechazo de esta prueba. Por simplicidad hemos omitido especificar los grados de libertad en la notación para los valores \(\chi_{\alpha/2}^2\) y \(\chi_{1-\alpha/2}^2\).
Código
# Parámetro n para el ejemplo
n_param <- 10
# Crear datos para la distribución gamma(n, 1)
x <- seq(0, 30, length.out = 1000)
y <- dchisq(x, df = n_param)
# Valores críticos
ji_low <- qchisq(0.025, df = n_param)
ji_up <- qchisq(0.975, df = n_param)
ji_medio <- mean(c(ji_low, ji_up))
# Crear el gráfico
ggplot(data.frame(x = x, y = y), aes(x, y)) +
geom_line(linewidth = 1) +
# Área central (1-alpha)
geom_area(data = data.frame(x = x[x >= ji_low & x <= ji_up],
y = y[x >= ji_low & x <= ji_up]),
aes(x, y), fill = "darkolivegreen", alpha = 0.7) +
# Áreas en las colas
geom_area(data = data.frame(x = x[x <= ji_low],
y = y[x <= ji_low]),
aes(x, y), fill = "darkolivegreen3", alpha = 0.5) +
geom_area(data = data.frame(x = x[x >= ji_up],
y = y[x >= ji_up]),
aes(x, y), fill = "darkolivegreen3", alpha = 0.5) +
# Líneas verticales
geom_vline(xintercept = c(ji_low, ji_up), linetype = "dashed") +
# Anotaciones
annotate("label", x = ji_low, y = -0.01,
label = "chi[1-alpha/2]^2", parse = TRUE, size = 4) +
annotate("label", x = ji_up, y = -0.01,
label = "chi[alpha/2]^2", parse = TRUE, size = 4) +
annotate("text", x = 0, y = 0.01, label = "alpha/2", parse = TRUE, size = 5) +
annotate("text", x = 25, y = 0.01, label = "alpha/2", parse = TRUE, size = 5) +
# Texto "Rechazar H₀"
annotate("label", x = ji_medio, y = 0.06, label = "Rechazar~H[0]", parse =TRUE,
size = 5, hjust = 0.5, vjust = 0.5) +
# Flechas apuntando a la región
annotate("curve", x = ji_medio+5, y = 0.055, xend = 25, yend = 0.015,
arrow = arrow(length = unit(0.02, "npc")),
curvature = -0.3, color = "black") +
annotate("curve", x = ji_medio-5, y = 0.055, xend = 0, yend = 0.015,
arrow = arrow(length = unit(0.02, "npc")),
curvature = 0.3, color = "black") +
labs(x = "x", y = expression(f(x))) +
theme_minimal() +
theme(axis.title = element_text(size = 12))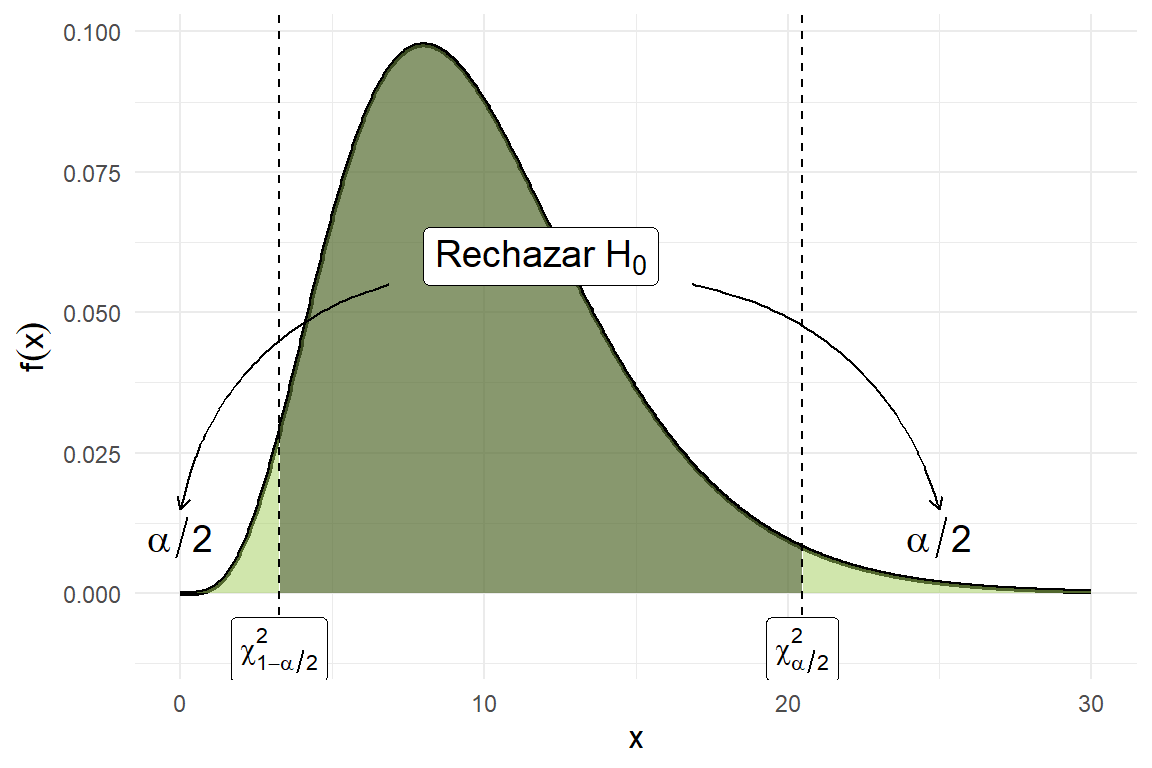
Sea \(\sigma_1^2\) cualquier número positivo distinto de \(\sigma_0^2\). La probabilidad de no rechazar \(H_0\) cuando el valor de la varianza es \(\sigma_1^2\) es
\[\beta(\sigma_1^2) = P(\text{"No rechazar } H_0\text{"} | \sigma^2 = \sigma_1^2) = P\left(\chi_{1-\alpha/2}^2 < \frac{(n - 1)S^2}{\sigma_0^2} < \chi_{\alpha/2}^2 | \sigma^2 = \sigma_1^2\right)\]
\[= P\left(\chi_{1-\alpha/2}^2 \cdot \frac{\sigma_0^2}{\sigma_1^2} < \frac{(n - 1)S^2}{\sigma_1^2} < \chi_{\alpha/2}^2 \cdot \frac{\sigma_0^2}{\sigma_1^2} | \sigma^2 = \sigma_1^2\right)\]
\[= F(\chi_{\alpha/2}^2 \cdot \sigma_0^2/\sigma_1^2) - F(\chi_{1-\alpha/2}^2 \cdot \sigma_0^2/\sigma_1^2),\]
en donde \(F\) es la función de distribución \(\chi^2(n - 1)\).
6.5.4.2 Prueba de cola inferior
Para la prueba que tiene como hipótesis alternativa \(H_1 : \sigma^2 < \sigma_0^2\) se propone como región de rechazo
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \chi_0^2 < \chi_{1-\alpha}^2\},\]
en donde \(\chi_{1-\alpha}^2\) es el número real tal que la distribución \(\chi^2(n - 1)\) acumula a la derecha probabilidad \(1 - \alpha\). Así, la región de rechazo se puede identificar como la cola de la izquierda de área \(\alpha\) de la distribución \(\chi^2(n-1)\). Esta es, por lo tanto, una región de rechazo de tamaño \(\alpha\). Para cualquier valor positivo \(\sigma_1^2\) menor a \(\sigma_0^2\), la probabilidad de no rechazar \(H_0\) cuando el valor de la varianza es \(\sigma_1^2\) es
\[\beta(\sigma_1^2) = P(\text{"No rechazar } H_0\text{"} | \sigma^2 = \sigma_1^2) = P\left(\frac{(n - 1)S^2}{\sigma_0^2} > \chi_{1-\alpha}^2 | \sigma^2 = \sigma_1^2\right)\]
\[= P\left(\frac{(n - 1)S^2}{\sigma_1^2} > \chi_{1-\alpha}^2 \cdot \frac{\sigma_0^2}{\sigma_1^2} | \sigma^2 = \sigma_1^2\right) = 1 - F(\chi_{1-\alpha}^2 \cdot \sigma_0^2/\sigma_1^2),\]
en donde \(F\) es la función de distribución \(\chi^2(n - 1)\).
6.5.4.3 Prueba de cola superior
Y finalmente para la prueba con hipótesis alternativa \(H_1 : \sigma^2 > \sigma_0^2\) se propone como región de rechazo
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \chi_0^2 > \chi_\alpha^2\},\]
en donde \(\chi_\alpha^2\) es el número real tal que la distribución \(\chi^2(n - 1)\) acumula a la derecha probabilidad \(\alpha\). Así, la región de rechazo se puede identificar como la cola de la derecha de área \(\alpha\) de la distribución \(\chi^2(n - 1)\). Esta es, por lo tanto, una región de rechazo de tamaño \(\alpha\). Para cualquier valor \(\sigma_1^2\) mayor a \(\sigma_0^2\), la probabilidad de no rechazar \(H_0\) cuando el valor de la varianza es \(\sigma_1^2\) es
\[\beta(\sigma_1^2) = P(\text{"No rechazar } H_0\text{"} | \sigma^2 = \sigma_1^2) = P\left(\frac{(n - 1)S^2}{\sigma_0^2} < \chi_\alpha^2 | \sigma^2 = \sigma_1^2\right)\]
\[= P\left(\frac{(n - 1)S^2}{\sigma_1^2} < \chi_\alpha^2 \cdot \frac{\sigma_0^2}{\sigma_1^2} | \sigma^2 = \sigma_1^2\right) = F(\chi_\alpha^2 \cdot \sigma_0^2/\sigma_1^2),\]
en donde \(F\) es la función de distribución \(\chi^2(n - 1)\).
6.6 Lema de Neyman-Pearson
Consideremos una distribución de probabilidad dependiente de un parámetro desconocido \(\theta\). Nos interesa llevar a cabo el contraste de dos hipótesis simples
\[H_0 : \theta = \theta_0 \quad vs \quad H_1 : \theta = \theta_1,\]
en donde \(\theta_0\) y \(\theta_1\) son dos posibles valores distintos del parámetro \(\theta\), los cuales supondremos fijos y conocidos. En esta situación, a la probabilidad complementaria del error tipo II, esto es, al número \(1 - \beta\) le hemos llamado potencia de la prueba. Considerando todas las posibles regiones de rechazo de tamaño \(\alpha\), a aquella que tenga potencia mayor se le llama prueba más potente.
El siguiente resultado, llamado lema de Neyman-Pearson, resuelve el problema de encontrar la región de rechazo más potente para la prueba indicada, es decir, proporciona la región de rechazo con probabilidad de error tipo II más pequeña.
Proposición 6.1 (Lema de Neyman-Pearson) La región de rechazo de tamaño \(\alpha\) más potente para el contraste de dos hipótesis simples
\[H_0 : \theta = \theta_0 \quad vs \quad H_1 : \theta = \theta_1,\]
está dada por
\[\mathscr{C} = \{(x_1,\ldots,x_n) : \frac{L(x_1,\ldots,x_n, \theta_1)}{L(x_1,\ldots,x_n, \theta_0)} \geq c\}\]
en donde \(L(x_1,\ldots,x_n; \theta)\) es la función de verosimilitud de una muestra aleatoria y \(c\) es una constante que hace que esta región de rechazo sea de tamaño \(\alpha\).