Nota: El contenido de esta sección es una adaptación al formato Quarto del capítulo 3 del libro Introducción a la Estadística Inferencial de Luis Rincón (2019).
En algunos casos es preferible brindar una estimación del parámetro poblacional en forma de intervalo, en lugar de solamente un valor puntual. En este tipo de estimación se busca un intervalo de extremos aleatorios, de tal forma que se pueda afirmar con un cierto nivel de confiabilidad, que el valor del parámetro desconocido se encuentra dentro de dicho intervalo. A este intervalo se le denomina intervalo de confianza y fueron desarrollados por Jerzy Neyman en 1937.
En esta sección se estudiarán los conceptos básicos de la estimación por intervalos, y se verán algunoos ejemplos de aplicación.
5.1 Definiciones
Como antes, consideraremos que tenemos una cierta variable aleatoria de interés que tiene función de densidad o de probabilidad conocida \(f(x;\theta)\), pero dependiente de un parámetro desconocido \(\theta\), el cual se requiere estimar a partir de una muestra aleatoria \(X_1, X_2, \ldots, X_n\) de esta distribución. A continuación se presenta la defición de intervalo de confianza.
Definición 5.1 Sea \(\alpha \in (0,1)\) un número fijo dado. Un intervalo de confianza para un parámetro desconocido \(\theta\) de una distribución de probadilidad es un intervalo aleatorio de la forma \((\hat{\theta}_1, \hat{\theta}_2)\), en donde \(\hat{\theta}_1\) y \(\hat{\theta}_2\) son dos estadísticas que satisfacen
A las estadísticas \(\hat{\theta}_1\) y \(\hat{\theta}_2\) se les denomina límites inferior y superior, respectivamente, del intervalo de confianza. El valor \(\alpha\) se denomina nivel de significancia y al número \(1 - \alpha\) se le llama nivel, grado o coeficiente de confianza del intervalo. En general, se toma un valor de \(\alpha\) cercano a cero, de tal forma que el nivel de confianza \(1 - \alpha\) sea cercano a uno. En la práctica, los valores más comunes de \(\alpha\) son 0.10, 0.05 y 0.01, de modo que que los grados de confianza \(1-\alpha\) correspondientes son 0.90, 0.95 y 0.99. Y decimos que los grados de confianza son del 90%, 95% y 99%, respectivamente.
Dado que los límites inferior y superior del intervalo de confianza son funciones de una muestra aleatoria \(X_1, X_2, \ldots, X_n\), al tomar estas variables aleatorias distintos valores se generan distintas realizaciones del intervalo de confianza, por lo tanto, los límites del intervalo de confianza son variables aleatorias. Algunas realizaciones del intervalo de confianza pueden contener el valor del parámetro desconocido \(\theta\), mientras que otras no. Usando la interpretación frecuentista de la probabilidad, podemos afirmar que en un gran número de realizaciones del intervalo aleatorio, el \(100(1-\alpha)\%\) de estas realizaciones contendrá el valor del parámetro desconocido \(\theta\) a estimar.
Observemos que no es correcto afirmar que la probabilidad de que el parámetro \(\theta\) se encuentre en el intervalo de confianza \((\hat{\theta_1}, \hat{\theta_2})\) es \(1-\alpha\), pues desde la perspectiva clásica, el parámetro \(\theta\) es un valor fijo desconocido, y por lo tanto no es una variable aleatoria. Lo que sí es correcto afirmar es que el \(100(1-\alpha)\%\) de los intervalos de confianza \((\hat{\theta_1}, \hat{\theta_2})\) construidos de esta manera contendrán al valor del parámetro \(\theta\). Podemos plantear el problema fundamental de la estimación por intervalos de la siguiente manera.
NotaProblema fundamental de la estimación por intervalos
Dado un nivel de significancia \(\alpha \in (0,1)\), encontrar dos estadísticas \(\hat{\theta}_1\) y \(\hat{\theta}_2\) tales que
El método pivotal es una técnica general para resolver el problema fundamental de la estimación por intervalos. A continuación se presenta la definición de esta técnica.
5.2 Método pivotal
Este método supone poder encontrar una función de la muestra y del parámetro desconocido, denotemos tal función como \(q(X_1, X_2, \ldots, X_n; \theta)\), con una distribución de probabilidad conocida, es decir, independiente del valor del parámetro \(\theta\) y de tal manera que puedan determinarse dos números \(a<b\) tales que \[P(a < q(X_1, X_2, \ldots, X_n; \theta) < b) = 1 - \alpha.\]
A partir de esta expresión se debe buscar desprender el término \(\theta\) del evento determinado por las desigualdades y encontrar dos estadísticas \(\hat{\theta}_1\) y \(\hat{\theta}_2\) que satisfagan la ecuación \(\eqref{eq-intconf}\), de modo que estas estadísticas puedan usarse como límites del intervalo de confianza. La función \(q(X_1, X_2, \ldots, X_n; \theta)\) se denomina estadístico, cantidad pivotal o simplemente pivote y es la base del método para encontrar los límites del intervalo de confianza. En resumen, el método pivotal consiste en encontrar un pivote y usarlo para determinar los límites del intervalo de confianza.
A continuación se presentan algunos ejemplos de aplicación del método pivotal para encontrar intervalos de confianza para distintos parámetros de algunas distribuciones de probabilidad conocidas.
5.3 Distribución Bernoulli
Supongamos que una cierta variable aleatoria de interés tiene distribución \(\text{Ber}(\theta)\), en donde el parámetro \(\theta\) es desconocido. Deseamos estimar este parámetro mediante un intervalo de confianza. Sea \(X_1,\ldots,X_n\) una muestra aleatoria de esta distribución. Haremos uso del hecho de que un estimador puntual para \(\theta\) es \(\overline{X}\), en donde \(E(\overline{X}) = \theta\) y \(\text{Var}(\bar{X}) = \theta(1-\theta)/n\). Por el teorema central del límite, de manera aproximada,
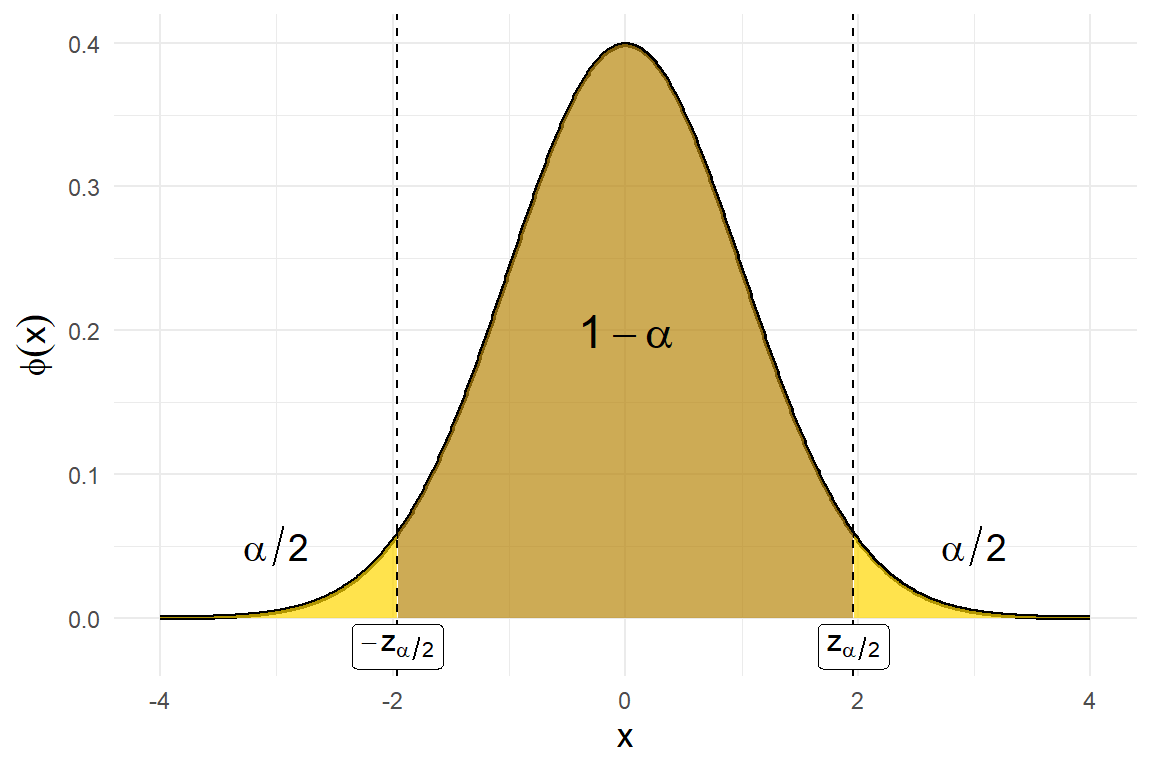
Por medio las funciones de la distribución normal *norm en R, se pueden encontrar dos valores \(a\) y \(b\) tales que la probabilidad de que esta variable aleatoria tome un valor entre \(a\) y \(b\) sea igual a \(1-\alpha\). Como es deseable que la longitud del intervalo \((a,b)\) sea de la menor longitud posible y como la distribución normal estándar es simétrica alrededor del origen, resulta que el intervalo \((a,b)\) de longitud mínima debe ser también simétrico alrededor del origen. Así, puede encontrarse un valor positivo, que denotaremos por \(z_{\alpha/2}\), tal que se cumple lo siguiente:
En la siguiente figura se muestra la distribución normal estándar y el intervalo simétrico de menor longitud alrededor del origen que cumple \(\eqref{eq-psim}\). El valor \(z_{\alpha/2}\) puede encontrarse con la función qnorm(1 - alpha/2) en R.
Código
# Crear datos para la curva normalx <-seq(-4, 4, length.out =1000)y <-dnorm(x)# Valor crítico para alpha = 0.05z_alpha <-qnorm(0.975)# Crear el gráficoggplot(data.frame(x = x, y = y), aes(x, y)) +geom_line(linewidth =1) +# Área central (1-alpha)geom_area(data =data.frame(x = x[x >=-z_alpha & x <= z_alpha], y = y[x >=-z_alpha & x <= z_alpha]),aes(x, y), fill ="darkgoldenrod", alpha =0.7) +# Áreas en las colas (alpha/2 cada una)geom_area(data =data.frame(x = x[x <=-z_alpha], y = y[x <=-z_alpha]),aes(x, y), fill ="gold1", alpha =0.7) +geom_area(data =data.frame(x = x[x >= z_alpha], y = y[x >= z_alpha]),aes(x, y), fill ="gold1", alpha =0.7) +# Líneas verticalesgeom_vline(xintercept =c(-z_alpha, z_alpha), linetype ="dashed") +# Anotacionesannotate("label", x =-z_alpha, y =-0.02, label ="-z[alpha/2]", parse =TRUE, size =4) +annotate("label", x = z_alpha, y =-0.02, label ="z[alpha/2]", parse =TRUE,size =4) +annotate("text", x =-3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =0, y =0.2, label ="1-alpha", parse=TRUE, size =6) +labs(x ="x", y =expression(phi(x))) +theme_minimal() +theme(axis.title =element_text(size =13))
Figura 5.1: Distribución normal estándar con intervalo simétrico
El problema consiste en encontrar \(\theta\) a partir de las dos desigualdades que aparecen en \(\eqref{eq-psim}\). Presentamos a continuación tres formas en que tal tarea puede llevarse a cabo de manera aproximada.
5.3.1 Primera solución
Una simplificación al problema planteado consiste en substituir el denominador \(\theta(1-\theta)/n\) por la estimación puntual \(\overline{X}(1-\overline{X})/n\). Es necesario admitir que esta substitución es una aproximación, pues el denominador original depende del parámetro desconocido \(\theta\), pero como resultado se obtendrá una cantidad pivotal a partir de la cual se producirá con facilidad una aproximación al intervalo buscado. Tenemos entonces la expresión
Observemos que este intervalo aleatorio tiene como centro la media muestral y se extiende a la derecha y a la izquierda la misma cantidad aleatoria. Por lo tanto, es un intervalo simétrico y su longitud total es la variable aleatoria
Otra alternativa para desprender de manera aproximada el parámetro \(\theta\) en la ecuación \(\eqref{eq-psim}\) es usar la desigualdad \(\theta(1-\theta) \leq 1/4\) para el denominador que aparece en esa ecuación. Nótese que la función \(f(x) = x(1-x)\), con \(x \in [0,1]\), alcanza su valor máximo en \(x = 1/2\) y dicho valor máximo es \(1/4\). Por lo tanto, para cualquier valor de \(\theta \in [0,1]\) se cumple que \(\theta(1-\theta) \leq 1/4\). Esta desigualdad produce la siguiente cota superior
Observemos que la longitud de este intervalo es no aleatoria \(L = z_{\alpha/2}/\sqrt{n}\), y que esta cantidad crece conforme la confianza \(1-\alpha\) se acerca a 1, y decrece conforme el tamaño de la muestra crece.
5.3.3 Tercera solución
Como una tercera alternativa para producir una cantidad pivotal de la ecuación (3.2), observemos que el evento en cuestión puede escribirse como \((|\bar{X} - \theta| < z_{\alpha/2}\sqrt{\theta(1-\theta)/n})\). Elevando al cuadrado y desarrollando se llega a la desigualdad
El intervalo encontrado sigue siendo una aproximación, es un intervalo no simétrico de longitud no aleatoria \(L = z_{\alpha/2}^2/(n + z_{\alpha/2}^2)\).
5.4 Distribución exponencial
Encontraremos un intervalo de confianza exacto para el parámetro de la distribución exponencial, a partir de una cantidad pivotal que construiremos a continuación. Sea \(X_1,\ldots,X_n\) una muestra aleatoria de la distribución \(\text{exp}(\theta)\). Sabemos que la variable aleatoria \(X_1+\cdots+X_n\) tiene distribución \(\text{gama}(n,\theta)\). Por otro lado, para cualquier constante \(c > 0\) y para cualquier variable aleatoria continua \(X\) con función de distribución \(F(x)\) y función de densidad \(f(x)\), se cumple que
Tomando \(c = \theta\) se encuentra que \(\theta(X_1+\cdots+X_n) \sim \text{gama}(n,1)\). Esta variable aleatoria involucra al parámetro \(\theta\) y su distribución está ahora completamente especificada. Esta es la cantidad pivotal buscada. Así, para cualquier valor \(\alpha \in (0,1)\), se pueden encontrar dos valores positivos \(a < b\) tales que
\[P(a < \theta(X_1+\cdots+X_n) < b) = 1-\alpha.\]
Una manera de determinar los valores de \(a\) y \(b\) es a través de las siguientes dos condiciones:
\[P(\theta(X_1+\cdots+X_n) < a) = \alpha/2,\]\[P(\theta(X_1+\cdots+X_n) > b) = \alpha/2.\]
Código
# Parámetro n para el ejemplon_param <-5# Crear datos para la distribución gamma(n, 1)x <-seq(0, 20, length.out =1000)y <-dgamma(x, shape = n_param, rate =1)# Valores críticosgamma_low <-qgamma(0.025, shape = n_param, rate =1)gamma_up <-qgamma(0.975, shape = n_param, rate =1)# Crear el gráficoggplot(data.frame(x = x, y = y), aes(x, y)) +geom_line(linewidth =1) +# Área central (1-alpha)geom_area(data =data.frame(x = x[x >= gamma_low & x <= gamma_up], y = y[x >= gamma_low & x <= gamma_up]),aes(x, y), fill ="chocolate3", alpha =0.7) +# Áreas en las colasgeom_area(data =data.frame(x = x[x <= gamma_low], y = y[x <= gamma_low]),aes(x, y), fill ="coral", alpha =0.5) +geom_area(data =data.frame(x = x[x >= gamma_up], y = y[x >= gamma_up]),aes(x, y), fill ="coral", alpha =0.5) +# Líneas verticalesgeom_vline(xintercept =c(gamma_low, gamma_up), linetype ="dashed") +# Anotacionesannotate("label", x = gamma_low, y =-0.01, label ="gamma[alpha/2]", parse =TRUE, size =4) +annotate("label", x = gamma_up, y =-0.01, label ="gamma[1-alpha/2]", parse =TRUE, size =4) +annotate("text", x =0, y =0.01, label ="alpha/2", parse =TRUE, size =4) +annotate("text", x =15, y =0.01, label ="alpha/2", parse =TRUE, size =4) +annotate("text", x =4, y =0.08, label ="1-alpha", parse =TRUE, size =5) +labs(x ="x", y =expression(f(x))) +theme_minimal() +theme(axis.title =element_text(size =12))
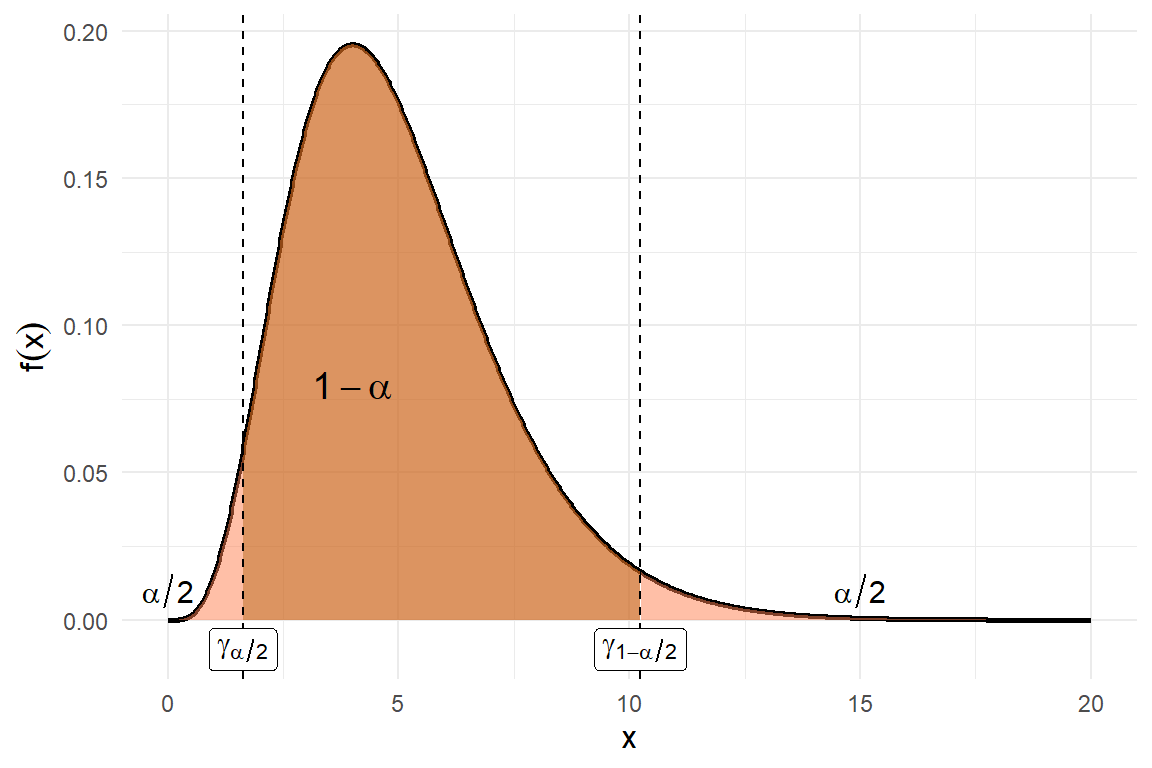
Figura 5.2: Función de densidad de la distribución gamma(n,1)
Véase la Figura 3.4 en donde se muestra la función de densidad de la distribución \(\text{gama}(n,1)\), el valor \(a\) se denota por \(\gamma_{1-\alpha/2}\) y el valor \(b\) por \(\gamma_{\alpha/2}\). Dado un valor de \(\alpha\), los valores para \(\gamma_{1-\alpha/2}\) y \(\gamma_{\alpha/2}\) pueden obtenerse de manera aproximada usando algún paquete computacional.
Observe que el intervalo considerado no necesariamente es el de longitud más pequeña, sin embargo, permite obtener el siguiente intervalo de confianza.
Proposición 5.4 Un intervalo de confianza para el parámetro de la distribución \(\text{exp}(\theta)\) está dado por
Encontraremos intervalos de confianza para los parámetros de una distribución normal en varias situaciones.
5.5.1 Intervalo para la media cuando la varianza es conocida
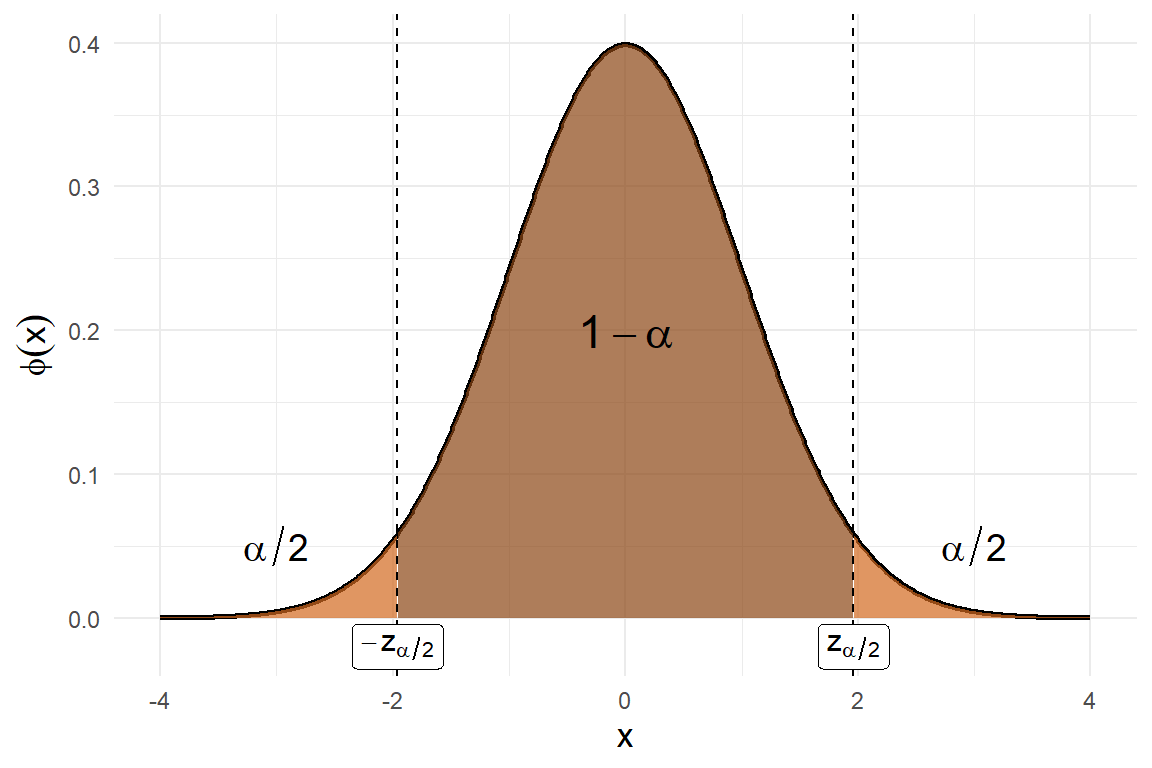
Sea \(X_1, ...., X_n\) una muestra aleatoria de una distribución normal con media desconocida \(\theta\) y varianza conocida \(\sigma^2\). Encontraremos un intervalo de confianza para \(\theta\). Como cada una de las variables de la muestra tiene distribución \(N(\theta,\sigma^2)\), la media muestral \(\overline{X}\) tiene distribución \(N(\theta, \sigma^2/n)\). De modo que, estandarizando, \[Z = \frac{\overline{X} - \theta}{\sigma/\sqrt{n}} \sim N(0,1).\] En esta situación, esta es la cantidad pivotal que nos ayudará a encontrar el intervalo de confianza buscado. Para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) un valor \(z_{\alpha/2}\) para la distribución normal estándar tal que (ver la siguiente figura) \[P\left(-z_{\alpha/2} < \frac{\overline{X} - \theta}{\sigma/\sqrt{n}} < z_{\alpha/2}\right) = 1-\alpha.\]
Código
# Crear datos para la curva normalx <-seq(-4, 4, length.out =1000)y <-dnorm(x)# Valor crítico para alpha = 0.05z_alpha <-qnorm(0.975)# Crear el gráficoggplot(data.frame(x = x, y = y), aes(x, y)) +geom_line(linewidth =1) +# Área central (1-alpha)geom_area(data =data.frame(x = x[x >=-z_alpha & x <= z_alpha], y = y[x >=-z_alpha & x <= z_alpha]),aes(x, y), fill ="chocolate4", alpha =0.7) +# Áreas en las colas (alpha/2 cada una)geom_area(data =data.frame(x = x[x <=-z_alpha], y = y[x <=-z_alpha]),aes(x, y), fill ="chocolate", alpha =0.7) +geom_area(data =data.frame(x = x[x >= z_alpha], y = y[x >= z_alpha]),aes(x, y), fill ="chocolate", alpha =0.7) +# Líneas verticalesgeom_vline(xintercept =c(-z_alpha, z_alpha), linetype ="dashed") +# Anotacionesannotate("label", x =-z_alpha, y =-0.02, label ="-z[alpha/2]", parse =TRUE, size =4) +annotate("label", x = z_alpha, y =-0.02, label ="z[alpha/2]", parse =TRUE,size =4) +annotate("text", x =-3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =0, y =0.2, label ="1-alpha", parse=TRUE, size =6) +labs(x ="x", y =expression(phi(x))) +theme_minimal() +theme(axis.title =element_text(size =13))
Figura 5.3: Distribución normal estándar con intervalo simétrico
Como la función de densidad de la distribución normal estándar es simétrica alrededor del origen, el intervalo \((-z_{\alpha/2}, z_{\alpha/2})\) es el intervalo simétrico de menor longitud alrededor del origen y sobre el cual la función de densidad cubre un área igual a \(1-\alpha\).
Resolviendo las dos desigualdades para \(\theta\) se obtiene el siguiente resultado.
Proposición 5.5 Un intervalo de confianza para la media \(\theta\) de una distribución normal con varianza conocida \(\sigma^2\) está dado por
Observemos que este intervalo es simétrico alrededor de la media muestral y su longitud es la cantidad no aleatoria
\[L = 2z_{\alpha/2}\sigma/\sqrt{n}\].
De aquí pueden obtenerse varias observaciones:
La longitud del intervalo decrece conforme el tamaño de la muestra crece, es decir, mientras mayor información se tenga más preciso es el intervalo. En el límite cuando \(n \to \infty\), el intervalo se colapasa en el estimador puntual \(\overline{X}\).
Si la confianza requerida crece, es decir, si \(1-\alpha\) se acerca a 1, entonces el valor \(z_{\alpha/2}\) crece y por lo tanto la longitud del intervalo también crece. Esto es razonable pues a mayor confianza se requiere un intervalo más amplio.
Si la dispersión de los datos es alta, es decir, si la desviación estándar \(\sigma\) es grande, entonces la longitud del intervalo tiende a ser grande.
Tamaño de la muestra
En el procedimiento para obtener el intervalo de confianza, se obtuvo
Es decir, si denotamos el error como \(e=|\overline{X}-\theta|\), la desigualdad anterior nos indica que \(e<z_{\alpha/2}\sigma/\sqrt{n}\) con probabilidad \(1-\alpha\). Por lo tanto, en situaciones donde es posible controlar el tamaño de la muestra \(n\), éste se puede escoger para acotar el error \(e\). El tamaño de muestra \(n\) apropiado se escoge de tal manera que \(z_{\alpha/2}\sigma/\sqrt{n}=e\), resolviendo esta igualdad para \(n\) se obtiene el siguiente resultado.
Proposición 5.6 Si se utiliza la media muestral \(\overline{X}\) para estimar la media desconocida de una variable aleatoria \(X\sim N(\theta, \sigma^2)\) con varianza conocida, con una confianza del \((1-\alpha)100\%\) el error \(|\overline{X}-\theta|\) no excede una cantidad dada \(E\) cuando el tamaño de muestra es \[n=\left(\frac{z_{\alpha/2}\sigma}{E}\right)^2.\]
5.5.2 Intervalo para la media cuando la varianza es desconocida
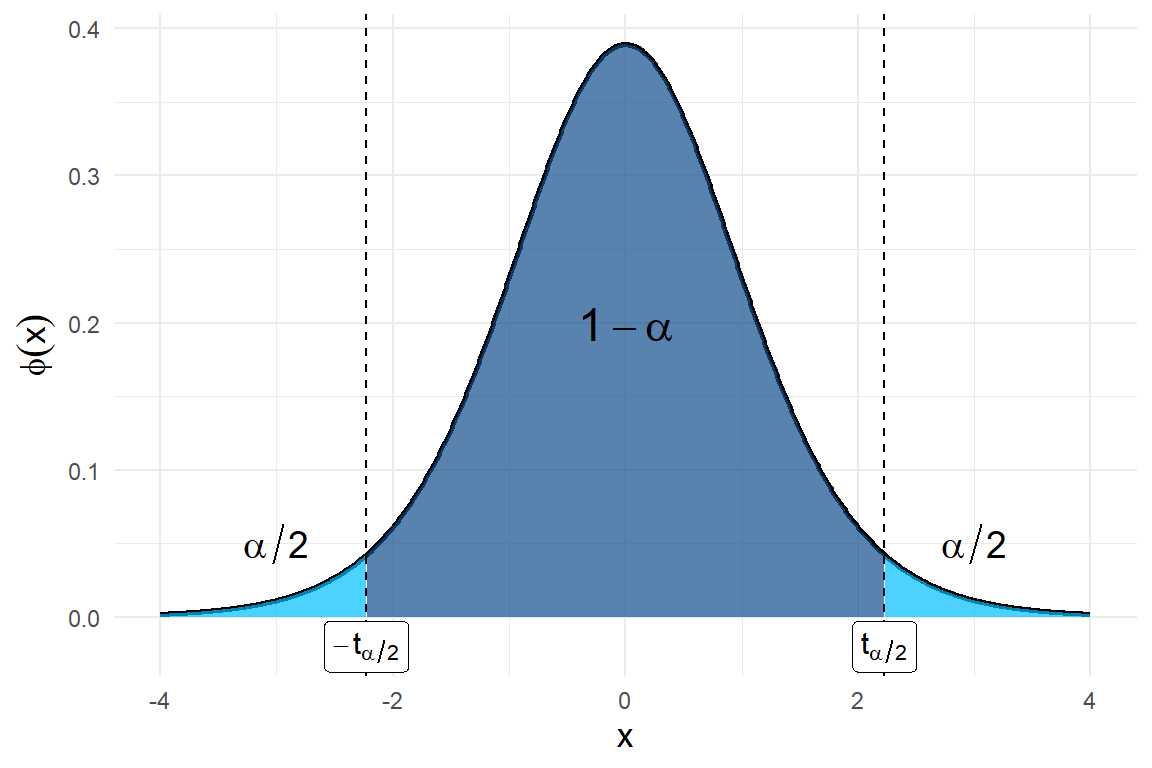
Consideremos nuevamente una muestra aleatoria \(X_1, \ldots, X_n\) de una distribución normal con media desconocida \(\theta\), pero ahora con varianza desconocida. El resultado teórico que utilizaremos es el siguiente: \[T = \frac{\overline{X} - \theta}{S/\sqrt{n}} \sim t(n-1).\] Observemos que esta variable aleatoria involucra al parámetro desconocido \(\theta\) y su distribución está completamente especificada para \(n\geq 2\). Tal variable aleatoria tiene distribución \(t\) de Stundent con \(n-1\) grados de libertad. Esta es la cantidad pivotal que nos ayudará a encontrar el intervalo de confianza buscado. Para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) un valor \(t_{\alpha/2}>0\) para la distribución \(t(n-1)\) tal que (ver la siguiente figura) \[P\left(-t_{\alpha/2} < \frac{\overline{X} - \theta}{S/\sqrt{n}} < t_{\alpha/2}\right) = 1-\alpha.\]
Código
# Crear datos para la curva normalx <-seq(-4, 4, length.out =1000)y <-dt(x, df =10)# Valor crítico para alpha = 0.05t_alpha <-qt(0.975, df =10)# Crear el gráficoggplot(data.frame(x = x, y = y), aes(x, y)) +geom_line(linewidth =1) +# Área central (1-alpha)geom_area(data =data.frame(x = x[x >=-t_alpha & x <= t_alpha], y = y[x >=-t_alpha & x <= t_alpha]),aes(x, y), fill ="dodgerblue4", alpha =0.7) +# Áreas en las colas (alpha/2 cada una)geom_area(data =data.frame(x = x[x <=-t_alpha], y = y[x <=-t_alpha]),aes(x, y), fill ="deepskyblue", alpha =0.7) +geom_area(data =data.frame(x = x[x >= t_alpha], y = y[x >= t_alpha]),aes(x, y), fill ="deepskyblue", alpha =0.7) +# Líneas verticalesgeom_vline(xintercept =c(-t_alpha, t_alpha), linetype ="dashed") +# Anotacionesannotate("label", x =-t_alpha, y =-0.02, label ="-t[alpha/2]", parse =TRUE, size =4) +annotate("label", x = t_alpha, y =-0.02, label ="t[alpha/2]", parse =TRUE,size =4) +annotate("text", x =-3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =3, y =0.05, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =0, y =0.2, label ="1-alpha", parse=TRUE, size =6) +labs(x ="x", y =expression(phi(x))) +theme_minimal() +theme(axis.title =element_text(size =13))
Figura 5.4: Distribución t de Student
Debido a la simetría alrededor del origen de la función de densidad de la distribución \(t(n-1)\), el intervalo \((-t_{\alpha/2,n-1}, t_{\alpha/2,n-1})\) es el intervalo simétrico de menor longitud alrededor del origen y sobre el cual la función de densidad cubre un área igual a \(1-\alpha\). Resolviendo las dos desigualdades para \(\theta\) se obtiene el siguiente resultado.
Proposición 5.7 Un intervalo de confianza para la media \(\theta\) de una distribución normal con varianza desconocida está dado por \[P\left(\overline{X} - t_{\alpha/2}\frac{S}{\sqrt{n}} < \theta < \overline{X} + t_{\alpha/2}\frac{S}{\sqrt{n}}\right) = 1-\alpha.\]
De este modo, el intervalo \[\left(\overline{X} - t_{\alpha/2}\frac{S}{\sqrt{n}}, \overline{X} + t_{\alpha/2}\frac{S}{\sqrt{n}}\right)\] es un intervalo de confianza para la media \(\theta\) de una población normal sin suponer la varianza conocida. La longitud de tal intervalo es la cantidad no aleatoria \[L = 2t_{\alpha/2}\frac{S}{\sqrt{n}}.\]
5.5.3 Intervalo para la varianza
Encontraremos un intervalo de confianza para la varianza \(\theta^2\) de una distribución normal. El resultado teórico que utilizaremos es el siguiente: dada una muestra aleatoria \(X_1, \dots, X_n\) de tamaño \(n\) de esta distribución, \[(n-1)\frac{S^2}{\theta^2} \sim \chi^2(n-1).\]
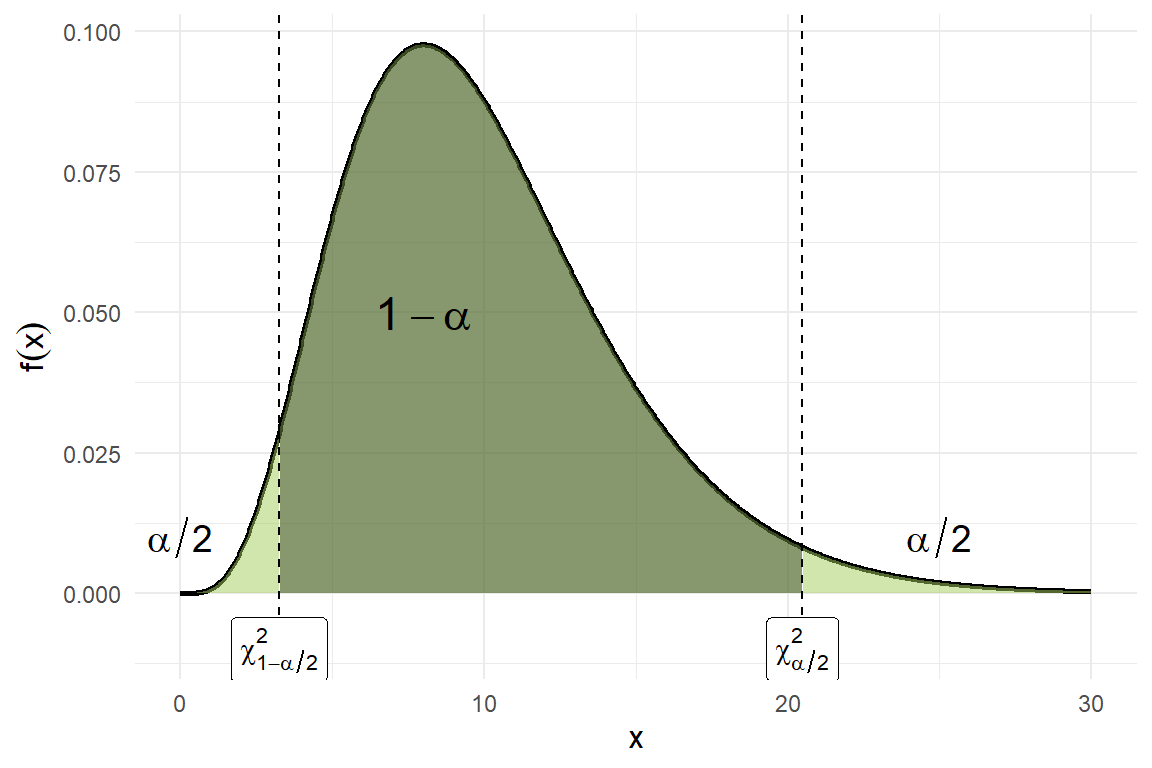
Esta es la cantidad pivotal que nos ayudará a encontrar el intervalo de confianza buscado. Para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) dos valores positivos \(0<\chi^2_{1-\alpha/2}<\chi^2_{\alpha/2}\) para la distribución ji-cuadrada con \(n-1\) grados de libertad tales que (ver la siguiente figura)
# Parámetro n para el ejemplon_param <-10# Crear datos para la distribución gamma(n, 1)x <-seq(0, 30, length.out =1000)y <-dchisq(x, df = n_param)# Valores críticosji_low <-qchisq(0.025, df = n_param)ji_up <-qchisq(0.975, df = n_param)# Crear el gráficoggplot(data.frame(x = x, y = y), aes(x, y)) +geom_line(linewidth =1) +# Área central (1-alpha)geom_area(data =data.frame(x = x[x >= ji_low & x <= ji_up], y = y[x >= ji_low & x <= ji_up]),aes(x, y), fill ="darkolivegreen", alpha =0.7) +# Áreas en las colasgeom_area(data =data.frame(x = x[x <= ji_low], y = y[x <= ji_low]),aes(x, y), fill ="darkolivegreen3", alpha =0.5) +geom_area(data =data.frame(x = x[x >= ji_up], y = y[x >= ji_up]),aes(x, y), fill ="darkolivegreen3", alpha =0.5) +# Líneas verticalesgeom_vline(xintercept =c(ji_low, ji_up), linetype ="dashed") +# Anotacionesannotate("label", x = ji_low, y =-0.01, label ="chi[1-alpha/2]^2", parse =TRUE, size =4) +annotate("label", x = ji_up, y =-0.01, label ="chi[alpha/2]^2", parse =TRUE, size =4) +annotate("text", x =0, y =0.01, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =25, y =0.01, label ="alpha/2", parse =TRUE, size =5) +annotate("text", x =8, y =0.05, label ="1-alpha", parse =TRUE, size =6) +labs(x ="x", y =expression(f(x))) +theme_minimal() +theme(axis.title =element_text(size =12))
Figura 5.5: Función de densidad de la distribución ji cuadrada
El intervalo \((\chi^2_{1-\alpha/2}, \chi^2_{\alpha/2})\) no es necesariamente el intervalo de menor longitud, pero es tal que \[P\left(\chi^2_{1-\alpha/2} < (n-1)\frac{S^2}{\theta^2} < \chi^2_{\alpha/2}\right) = 1-\alpha.\]
Resolviendo las dos desigualdades para \(\theta^2\) se obtiene el siguiente resultado.
Proposición 5.8 Un intervalo de confianza para la varianza \(\theta^2\) de una distribución normal está dado por \[P\left(\frac{(n-1)S^2}{\chi^2_{\alpha/2}} < \theta^2 < \frac{(n-1)S^2}{\chi^2_{1-\alpha/2}}\right) = 1-\alpha.\]
De este modo, el intervalo \[\left(\frac{(n-1)S^2}{\chi^2_{\alpha/2}}, \frac{(n-1)S^2}{\chi^ 2_{1-\alpha/2}}\right)\] es un intervalo de confianza para la varianza \(\theta^2\) de una población normal. La longitud de tal intervalo es la cantidad no aleatoria \[L = (n-1)S^2\left(\frac{1}{\chi^2_{1-\alpha/2}} - \frac{1}{\chi^2_{\alpha/2}}\right).\]
5.5.4 Intervalo para la diferencia de medias cuando las varianzas son conocidas
Sea \(X_1, ...., X_n\) una muestra aleatoria de una distribución normal \(N(\theta_1, \sigma^2_1)\) con media desconocida \(\theta_1\) y varianza conocida \(\sigma_1^2\), y sea \(Y_1, ...., Y_m\) otra muestra aleatoria con distribución normal, independiente de la primera, con media desconocida \(\theta_2\) y varianza conocida \(\sigma_2^2\). Encontraremos un intervalo de confianza para la diferencia de las medias \(\theta_1 - \theta_2\). Como cada una de las variables de la primera muestra tiene distribución \(N(\theta_1,\sigma_1^2)\), la media muestral \(\overline{X} \sim N(\theta_1, \sigma_1^2/n)\). De modo similar, la media muestral \(\overline{Y}\sim N(\theta_2, \sigma_2^2/m)\). Por lo tanto, la variable aleatoria \(\overline{X} - \overline{Y}\) tiene distribución normal con media \(\theta_1 - \theta_2\) y varianza \(\sigma_1^2/n + \sigma_2^2/m\). Estandarizando, \[Z = \frac{(\overline{X} - \overline{Y}) - (\theta_1 - \theta_2)}{\sqrt{\sigma_1^2/n + \sigma_2^2/m}} \sim N(0,1).\] Ensta situación, esta es la cantidad pivotal que nos ayudará a encontrar el intervalo de confianza buscado. Para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) un valor \(z_{\alpha/2}\) para la distribución normal estándar tal que \[P\left(-z_{\alpha/2} < \frac{(\overline{X} - \overline{Y}) - (\theta_1 - \theta_2)}{\sqrt{\sigma_1^2/n + \sigma_2^2/m}} < z_{\alpha/2}\right) = 1-\alpha.\]
En este caso, el intervalo simétrico indicado es el de longitud mínima que satisface la condición anterior. De aquí se puede obtener el intervalo de confianza buscado.
Proposición 5.9 Un intervalo de confianza al \((1-\alpha)100\%\) para la diferencia de medias \(\theta_1 - \theta_2\) de dos distribuciones normales \(N(\theta_1, \sigma^2_1)\) y \(N(\theta_2, \sigma^2_2\), con varianzas conocidas \(\sigma_1^2\) y \(\sigma_2^2\) está dado por \[P\left((\overline{X} - \overline{Y}) - z_{\alpha/2}\sqrt{\sigma_1^2/n + \sigma_2^2/m} < \theta_1 - \theta_2 < (\overline{X} - \overline{Y}) + z_{\alpha/2}\sqrt{\sigma_1^2/n + \sigma_2^2/m}\right) = 1-\alpha.\]
O bien, \[(\overline{X} - \overline{Y}) \pm z_{\alpha/2}\sqrt{\sigma_1^2/n + \sigma_2^2/m}.\]
5.5.5 Intervalo para la diferencia de medias cuando las varianzas son desconocidas pero iguales
Consideremos nuevamente que \(X_1, ...., X_n\) es una muestra aleatoria de una distribución normal \(N(\theta_1, \sigma^2)\) con media desconocida \(\theta_1\) y varianza desconocida \(\sigma^2\), y que \(Y_1, ...., Y_m\) es otra muestra aleatoria con distribución normal \(N(\theta_2, \sigma^2)\), independiente de la primera, con media desconocida \(\theta_2\) y varianza desconocida \(\sigma^2\). Nótese que en este caso la varianza \(\sigma^2\) es común a ambas distribuciones. Se encontrará un intervalo de confianza para la diferencia \(\theta_1-\theta_2\). Definamos las siguientes varianzas muestrales
La última de estas variables aleatorias es la cantidad pivotal que nos ayudará a encontrar el intervalo de confianza buscado. Para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) un valor \(t_{\alpha/2}\) para la distribución \(t(n+m-2)\) tal que \[P\left(-t_{\alpha/2} < \frac{(\overline{X}-\overline{Y}) - (\theta_1 - \theta_2)}{S\sqrt{1/n + 1/m}} < t_{\alpha/2}\right) = 1-\alpha.\]
En este caso, el intervalo simétrico indicado es el de longitud mínima que satisface la condicioón aneterior. De aquí se puede obtener el intervalo de confianza buscado.
Proposición 5.10 Un intervalo de confianza al \((1-\alpha)100\%\) para la diferencia de medias \(\theta_1 - \theta_2\) de dos distribuciones normales \(N(\theta_1, \sigma^2)\) y \(N(\theta_2, \sigma^2\), con varianzas desconocidas pero iguales \(\sigma^2\) está dado por \[P\left((\overline{X} - \overline{Y}) - t_{\alpha/2}S\sqrt{1/n + 1/m} < \theta_1 - \theta_2 < (\overline{X} - \overline{Y}) + t_{\alpha/2}S\sqrt{1/n + 1/m}\right) = 1-\alpha.\] O bien, \[(\overline{X} - \overline{Y}) \pm t_{\alpha/2}S\sqrt{1/n + 1/m}\]
La longitud de este intervalo es la cantidad no aleatoria \[L = 2t_{\alpha/2}S\sqrt{1/n + 1/m}.\]
5.6 Intervalo para la media de una distribución cualquiera
Consideremos una distribución cualquiera cuya media es un parámetro desconocido \(\theta\) y una muestra aleatoria de tamaño \(n\) de esta distribución. Si \(n\) es suficientemente grande, con cierta confianza puede aplicarse el teorema central del límite, y entonces de manera aproximada tenemos que \[Z = \frac{\overline{X} - \theta}{S/\sqrt{n}} \sim N(0,1).\]
Ahora, para cualquier valor de \(\alpha \in (0,1)\) podemos encontrar (por medio de R) un valor \(z_{\alpha/2}\) para la distribución normal estándar tal que \[P\left(-z_{\alpha/2} < \frac{\overline{X} - \theta}{S/\sqrt{n}} < z_{\alpha/2}\right) \approx 1-\alpha.\] Resolviendo para \(\theta\) en las dos desigualdades se obtiene el siguiente intervalo de confianza.
Proposición 5.11 Un intervalo de confianza aproximado para la media \(\theta\) de una distribución cualquiera está dado por \[P\left(\overline{X} - z_{\alpha/2}\frac{S}{\sqrt{n}} < \theta < \overline{X} + z_{\alpha/2}\frac{S}{\sqrt{n}}\right) \approx 1-\alpha.\]